Содержание
О порядке заполнения СЗВ-М в отношении физических лиц, с которыми заключены договоры ГПХ
Ответ
|
Телеграм-канал https://t.me/knk_audit Бухучет, налоги, нововведения, прослеживаемость, иностранные компании, сложные случаи
|
В силу пункта 2.2 статьи 11 Федерального закона «Об индивидуальном (персонифицированном) учете в системе обязательного пенсионного страхования» от 01.04.1996 № 27-ФЗ (далее – Закон № 27-ФЗ) страхователь ежемесячно не позднее 15-го числа месяца, следующего за отчетным периодом — месяцем, представляет о каждом работающем у него застрахованном лице (включая лиц, заключивших договоры гражданско-правового характера, предметом которых являются выполнение работ, оказание услуг, договоры авторского заказа, договоры об отчуждении исключительного права на произведения науки, литературы, искусства, издательские лицензионные договоры, лицензионные договоры о предоставлении права использования произведения науки, литературы, искусства, в том числе договоры о передаче полномочий по управлению правами, заключенные с организацией по управлению правами на коллективной основе) следующие сведения:
1) страховой номер индивидуального лицевого счета;
2) фамилию, имя и отчество;
3) идентификационный номер налогоплательщика (при наличии у страхователя данных об идентификационном номере налогоплательщика застрахованного лица).
Таким образом, Организация обязана представлять сведения по форме СЗВ-М, в том числе в отношении физических лиц, с которыми заключены договоры гражданско-правового характера.
Форма СЗВ-М и Порядок ее заполнения утверждены Постановлением Правления ПФ РФ от 15.04.2021 № 103п (далее – Порядок заполнения формы СЗВ-М).
Согласно пункту 14 Порядка заполнения формы СЗВ-М в разделе 4 «Сведения о застрахованных лицах» указываются сведения о застрахованных лицах, на которых распространяется обязательное пенсионное страхование в соответствии со статьей 7 Федерального закона «Об обязательном пенсионном страховании в РФ» от 15.12.2001 № 167-ФЗ (далее – Закон № 167-ФЗ).
Пунктом 1 статьи 7 Закона № 167-ФЗ установлено, что застрахованные лица — лица, на которых распространяется обязательное пенсионное страхование в соответствии с настоящим Федеральным законом. Застрахованными лицами являются граждане РФ, постоянно или временно проживающие на территории РФ иностранные граждане или лица без гражданства, а также иностранные граждане или лица без гражданства[1], временно пребывающие на территории РФ, работающие по трудовому договору, в том числе руководители организаций, являющиеся единственными участниками (учредителями), членами организаций, собственниками их имущества, или по договору гражданско-правового характера, предметом которого являются выполнение работ и оказание услуг[2], по договору авторского заказа, а также авторы произведений, получающие выплаты и иные вознаграждения по договорам об отчуждении исключительного права на произведения науки, литературы, искусства, издательским лицензионным договорам, лицензионным договорам о предоставлении права использования произведения науки, литературы, искусства[3].
Таким образом, Организация обязана указывать сведения в СЗВ-М о тех физических лица, с которыми заключены договоры ГПХ, независимо от факта выплаты вознаграждения.
На основании изложенного, считаем, что за те месяцы, в которых физическим лицам, с которым заключен договор ГПХ, не производились выплаты, Организация обязана предоставлять сведения по форме СЗВ-М о таких физических лицах.
Коллегия Налоговых Консультантов, 8 августа 2022 года
|
Коллегия Налоговых Консультантов
оказывает и юридические услуги, в т.ч. по
налоговым проверкам +7915-329-02-05
|
[1] за исключением высококвалифицированных специалистов в соответствии с Федеральным законом «О правовом положении иностранных граждан в РФ» от 25. 07.2002 № 115-ФЗ.
07.2002 № 115-ФЗ.
[2] за исключением лиц, обучающихся в профессиональных образовательных организациях и образовательных организациях высшего образования по очной форме обучения и получающих выплаты за деятельность, осуществляемую в студенческом отряде по трудовым договорам или по гражданско-правовым договорам, предметом которых являются выполнение работ и (или) оказание услуг, лиц, применяющих специальный налоговый режим «Налог на профессиональный доход», получающих выплаты за деятельность по гражданско-правовым договорам и не работающих по трудовому договору, а также лиц, получающих страховые пенсии в соответствии с законодательством РФ, являющихся опекунами или попечителями, исполняющими свои обязанности возмездно по договору об осуществлении опеки или попечительства, в том числе по договору о приемной семье.
[3] за исключением лиц, применяющих специальный налоговый режим «Налог на профессиональный доход».
Ответы на самые интересные вопросы на нашем телеграм-канале
knk_audit
Назад в раздел
Многоклассовая классификация с методами опорных векторов (SVM), двойной задачей и функциями ядра | by Hucker Marius
Наконец-то понять концепцию SVM + Реализация в Python через scikit-learn к их склонности не перетренироваться, но во многих случаях хорошо работать.
 Если вас интересует только определенная тема, просто пролистайте темы. Вот темы в хронологическом порядке:
Если вас интересует только определенная тема, просто пролистайте темы. Вот темы в хронологическом порядке:
- Какая математическая концепция стоит за машиной опорных векторов?
- Что такое ядро и что такое функции ядра ?
- Что такое трюк ядра ?
- Что такое двойная задача SVM?
- Как работает Многоклассовая классификация ?
- Реализация с помощью Python и scikit-learn
Если вас интересует только то, как это можно реализовать с помощью Python и scikit-learn, прокрутите вниз до конца!
Начнем.
Цель состоит в том, чтобы найти гиперплоскость в n-мерном пространстве, которая разделяет точки данных на их потенциальные классы. Гиперплоскость должна располагаться на максимальном расстоянии от точек данных. Точки данных с минимальным расстоянием до гиперплоскости называются Опорные векторы . Из-за близкого расположения их влияние на точное положение гиперплоскости больше, чем у других точек данных. На графике ниже опорные векторы представляют собой 3 точки (2 синие, 1 зеленая), лежащие на линиях.
Гиперплоскость должна располагаться на максимальном расстоянии от точек данных. Точки данных с минимальным расстоянием до гиперплоскости называются Опорные векторы . Из-за близкого расположения их влияние на точное положение гиперплоскости больше, чем у других точек данных. На графике ниже опорные векторы представляют собой 3 точки (2 синие, 1 зеленая), лежащие на линиях.
источник: wikipedia (Larhmam)
SVM также называют ядром SVM из-за их ядра, которое преобразует пространство входных данных в многомерное пространство.
Входное пространство X состоит из x и x’.
представляет функцию ядра , которая превращает входное пространство в многомерное пространство, так что не каждая точка данных отображается явно.
Функция ядра также может быть записана как
То, как функция определена и полезна для прокладки гиперплоскостей, зависит от данных:
Функции ядра
Наиболее популярные функции ядра, которые также доступны в -learn are линейная, полиномиальная, радиальная базисная функция и сигмовидные .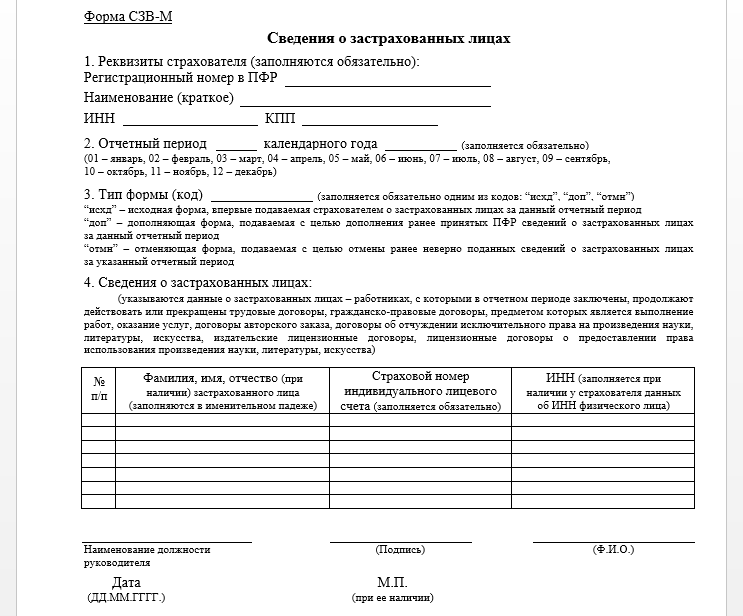 Для получения дополнительных функций посетите dataflair. Далее вы можете увидеть, как эти четыре функции ядра выглядят как:
Для получения дополнительных функций посетите dataflair. Далее вы можете увидеть, как эти четыре функции ядра выглядят как:
- Линейная функция
2. Полиномиальная функция
3. Функция радиальной базисной базис (RBF)
4. Sigmoid функция
4. Sigmoid функция
4. Sigmoid.
Что делает функция ядра?
Берет две точки данных x_n и x_m и вычисляет для них оценку расстояния. Этот показатель выше для более близких точек данных и наоборот. Использование этой оценки помогает преобразовать точки данных в многомерное отображение, что сокращает вычислительные усилия и время и особенно полезно для огромных объемов данных. Это предотвращает необходимость более сложной трансформации.
Вот почему этот шаг часто называют Уловка ядра .
Как видно на приведенном ниже рисунке, отображение точек данных превращается из 2D в 3D-пространство с помощью функции ядра (φ(( a , b )) = ( a , б , а 2 + б 2)). Ранее центрированные красные точки теперь также расположены вертикально ниже при повороте в 3D-пространство. Нечетко разделяемые точки данных теперь можно лучше разделить с помощью ядра.
Ранее центрированные красные точки теперь также расположены вертикально ниже при повороте в 3D-пространство. Нечетко разделяемые точки данных теперь можно лучше разделить с помощью ядра.
источник: wikipedia (Shiyu, Ji)
Кроме того, различные ядра могут помочь прокладывать гиперплоскости различной формы через облако точек данных. Очевидно, что пределы линейных гиперплоскостей быстро превышаются из-за их ограниченной приспособляемости к различным формам. На основе этого факта были разработаны различные функции ядра.
Следите за новыми статьями Мариуса Хукера
Следите за новыми статьями Мариуса Хакера Зарегистрировавшись, вы создадите учетную запись Medium, если у вас еще нет…
medium.com
Для лучшего понимания того, как может выглядеть разделение различных гиперплоскостей, различные виды функций ядра показаны на рисунке ниже.
Визуализация различных функций ядра.
Следующая формула представляет проблему оптимизации, которую решает SVM. Это объясняется ниже (scikit-learn, n.d.):
Это объясняется ниже (scikit-learn, n.d.):
Цель состоит в том, чтобы правильно классифицировать как можно больше точек данных, максимизируя разницу между Опорные векторы к гиперплоскости при минимизации члена
Другими словами, цель также может быть объяснена как нахождение оптимальных w и b , чтобы большинство выборок предсказывалось правильно.
В большинстве случаев не все точки данных могут быть размещены идеально, чтобы расстояние до правильного поля было представлено как
Вектор нормали создает линию, проходящую через начало координат. Гиперплоскости пересекают эту прямую ортогонально на расстоянии
от источника.
Для идеального случая (Bishop, p.325 ff., 2006)
было бы ≥ 1 и, следовательно, было бы точно предсказано. Имея теперь точки данных с расстоянием до их идеального положения, давайте скорректируем идеальный случай, когда ≥ 1, на
. Одновременно в формулу минимизации вводится штрафной член. C действует как параметр регуляризации и контролирует, насколько сильным является штраф в отношении того, сколько точек данных было ошибочно назначено с общим расстоянием
C действует как параметр регуляризации и контролирует, насколько сильным является штраф в отношении того, сколько точек данных было ошибочно назначено с общим расстоянием
Двойственная задача
Задачу оптимизации можно назвать двойственной задачей , пытающейся минимизировать параметры при максимальном запасе. Для решения двойственной задачи используются множители Лагранжа (альфа≥0).
Это приводит к лагранжевой функции (Bishop, p.325 ff., 2006):
Используя следующие два условия (Bishop, p.325 ff., 2006):
w и b можно исключить из L(ш,б,а) . Это приводит к следующей функции Лагранжа, которая максимизируется как (Bishop, p.325 ff., 2006):
При решении задачи оптимизации новые точки данных можно классифицировать с помощью (Bishop, p.325 ff., 2006): , полином, рбф) можно заполнить.
И все! Если бы вы могли следить за математикой, вы бы поняли принцип работы машины опорных векторов. Легко понять, как разделить облако точек данных на два класса, но как это сделать для нескольких классов?
Легко понять, как разделить облако точек данных на два класса, но как это сделать для нескольких классов?
Давайте посмотрим, как это работает.
В своем самом простом типе SVM применяется к бинарной классификации, разделяя точки данных либо на 1, либо на 0. Для многоклассовой классификации используется тот же принцип. Проблема мультикласса разбивается на несколько случаев бинарной классификации, которые также называются один против одного . В scikit-learn метод «один против одного» не используется по умолчанию и должен выбираться явно (как видно далее в коде). Один против остальных устанавливается по умолчанию. Он в основном делит точки данных в классе x и остальных. Последовательно определенный класс отличается от всех других классов.
Количество классификаторов, необходимое для многоклассовой классификации один против одного , можно получить по следующей формуле (где n — количество классов):
В подходе один против одного каждый классификатор разделяет точки два разных класса и включение всех классификаторов «один против одного» приводит к мультиклассовому классификатору.
Возможно, вам уже наскучил набор данных iris, но это самый простой способ продемонстрировать это, так что давайте взглянем на код. Некоторые части кода вы также можете найти в scikit-learn.
#Importing Необходимым пакеты и лигирьями
от Sklearn.metrics Импорт. набор данных радужной оболочки как радужную оболочку и сохранить целевые и характерные переменные:iris = datasets.load_iris() # Сохранить переменные как целевую у и первые две характеристики как X (длина чашелистиков и ширина чашелистиков цветков ириса)
X = iris.data[:, :2]
y = iris.targetА теперь давайте разделим набор данных на train и test-set для следующего обучения и прогнозирования:
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0,8, random_state = 0)На этом этапе мы рассмотрим различные функции ядра. Срок штрафа C установлен равным 1 для всех классификаторов. Для многоклассовой классификации указывается тип «один против одного», как это видно из решения solution_function_shape=’ovo’.
Для полиномиальной функции выбрана степень 3, для других функций ядра в этом нет необходимости.
Все остальные параметры установлены по умолчанию. Здесь вы можете узнать больше о SVC-функции scikit-learn.linear = svm.SVC(kernel='linear', C=1, solution_function_shape='ovo').fit(X_train, y_train)rbf = svm.SVC(kernel='rbf', gamma=1, C=1 . .SVC (ядро = 'сигмоид', C = 1, solution_function_shape = 'ovo'). Подходит (X_train, y_train)Теперь давайте укажем сетку, в которой мы будем отображать результаты.
#шаг в сетке, он изменяет точность печати
#чтобы лучше понять это, просто поиграйте со значением, измените его и напечатайте
h = .01 #создайте сетку
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1] .max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h)) # создаем заголовок, который будет отображаться на графике
titles = ['Линейное ядро','Ядро RBF','Полиномиальное ядро','Сигмовидное ядро']
Теперь мы будем использовать цикл for для построения графика всех 4 функций ядра:
for i, clf in enumerate((linear, rbf, poly, sig)):
# определяет количество графиков: 2 строки, 2 столбца => ведущие к 4 графикам
plt.
#пробел между графиками
plt.subplots_adjust(wspace=0.4, hspace=0.4) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # Поместите результат в цветной график
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.PuBuGn, alpha=0.7) # Также постройте график обучения точки
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.PuBuGn, edgecolors='grey') plt.xlabel('Длина чашелистика')
plt .ylabel('Ширина чашелистиков')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.title(titles[i]) plt.show()Как вы, наверное, уже поняли, результатом является изображение сверху в статье:
На следующем этапе мы делаем прогнозы для набора тестовых данных, используя наши 4 различные функции ядра:
linear_pred = linear.predict(X_test)
poly_pred = poly.predict(X_test)
rbf_pred = rbf.
sig_pred = sig.predict(X_test)Чтобы понять, насколько хорошо они работают, мы используем показатель производительности — точность.
# получить точность и вывести ее для всех 4 функций ядра
precision_lin = linear.score(X_test, y_test)
precision_poly = poly.score(X_test, y_test)
точность_rbf = rbf.score(X_test, y_test)
точность_sig = sig.score(X_test, y_test)print("Линейное ядро точности:", точность_lin)
print("Полиномиальная точность Ядро:», точность_поли)
печать («Точность ядра радиальной основы:», точность_rbf)
печать («Точность сигмоидального ядра:», точность_sigКак показывает точность, некоторые функции ядра более полезны, чем другие, в зависимости от данных , И очевидно, что больше данных также полезно для улучшения результатов (данные по радужной оболочке имеют не очень большой размер с 50 образцами :-)).
Давайте перейдем к последнему шагу — распечатке матриц путаницы для 4 функций ядра, чтобы понять, как и что было предсказано:
# создание матрицы путаницы
cm_lin = путаница_матрица (y_test, linear_pred)
cm_poly = путаница_матрица (y_test) , poly_pred)
cm_rbf = матрица_путаний(y_test, rbf_pred)
cm_sig = матрица_путаний(y_test, sig_pred)print(cm_lin)
print(cm_poly)
print(cm_rbf)
print(cm_sig)4 матрицы ошибок
Вот и все.
Спасибо за внимание, я ценю обратную связь!
Следите за новыми статьями Мариуса Хукера
Следите за новыми статьями Мариуса Хакера Зарегистрировавшись, вы создадите учетную запись Medium, если у вас еще нет…
medium.com
Источники
- Bishop, 2006, Распознавание образов и машинное обучение, стр. 325 и далее.
- Vapnik & Cortes, 1995, Сети опорных векторов
- Scikit-learn, Машины опорных векторов
- Scikit-learn, Постройте различные классификаторы SVM в наборе данных радужной оболочки
- Dataflair, Функции ядра — Введение в ядро SVM и примеры 0 0
Весь код
#Импорт необходимых пакетов и библиотек
из sklearn.metrics import путаница_матрица
из sklearn.model_selection import train_test_split
из sklearn import svm, наборы данных
import matplotlib.
import numpy as npiris = datasets.load_iris() ширина чашелистика цветков ириса)
X = iris.data[:, :2]
y = iris.targetlinear = svm.SVC(kernel='linear', C=1, solution_function_shape='ovo').fit( X_train, y_train)rbf = svm.SVC(kernel='rbf', gamma=1, C=1, solution_function_shape='ovo').fit(X_train, y_train)poly = svm.SVC(kernel='poly', степень =3, C=1, solution_function_shape='ovo').fit(X_train, y_train)sig = svm.SVC(kernel='sigmoid', C=1, solution_function_shape='ovo').fit(X_train, y_train) #stepsize в сетке, это изменяет точность plotprint
#чтобы лучше понять это, просто поиграйте со значением, измените его и напечатайте
h = .01 #создайте сетку
x_min, x_max = X [:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max () + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h)) # создаем заголовок, который будет отображаться на графике
заголовков = ['Линейное ядро','Ядро RBF','Полиномиальное ядро','Сигмовидное ядро']для i, clf in enumerate((linear, rbf, poly, sig)):
#определяет количество графиков: 2 строки, 2 столбца=> ведет к 4 графикам
plt.
#пробел между графиками
plt.subplots_adjust (wspace=0.4, hspace=0.4)Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # Поместите результат в цветной график
Z = Z.reshape(xx .shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.PuBuGn, alpha=0.7) # Также нанесите точки обучения
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.PuBuGn, edgecolors='grey')plt.xlabel('Длина чашелистика')
plt.ylabel('Ширина чашелистика')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(( ))
plt.yticks(())
plt.title(titles[i])plt.show()linear_pred = linear.predict(X_test)
poly_pred = poly.predict(X_test)
rbf_pred = rbf.predict(X_test) )
sig_pred = sig.predict(X_test) # получить точность и вывести ее для всех 4 функций ядра0127 точность_rbf = rbf.score(X_test, y_test)
точность_sig = sig.score(X_test, y_test)print("Линейное ядро точности:", точность_lin)
печать("Ядро полинома точности:", точность_поли)
печать("Точность Ядро радиального базиса:", точность_rbf)
print("Ядро сигмоиды точности:", точность_sig # создание матрицы путаницы
cm_lin = путаница_матрица (y_test, linear_pred)
cm_poly = путаница_матрица (y_test, poly_pred)
cm_rbf = путаница_матрица (y_test) , rbf_pred)
cm_sig = путаница_матрица (y_test, sig_pred) print (cm_lin)
print (cm_poly)
print (cm_rbf)
print (cm_sig)python - Как заставить SVM хорошо играть с отсутствующими данными в scikit-learn?
Задать вопрос
спросил
Изменено
1 год, 7 месяцев назадПросмотрено
16 тысяч разЯ использую scikit-learn для некоторого анализа данных, и в моем наборе данных есть некоторые пропущенные значения (представленные
NA).genfromtxtсdtype='f8'и приступаю к обучению своего классификатора.Классификация подходит для объектов
RandomForestClassifierиGradientBoostingClassifier, но с использованиемSVCизsklearn.svmвызывает следующую ошибку:probas = classifiers[i].fit(train[traincv], target[traincv]).predict_proba(train[testcv]) Файл "C:\Python27\lib\site-packages\sklearn\svm\base.py", строка 409, в predict_proba X = self._validate_for_predict(X) Файл "C:\Python27\lib\site-packages\sklearn\svm\base.py", строка 534, в _validate_for_predict X = atleast2d_or_csr(X, dtype=np.float64, order="C") Файл "C:\Python27\lib\site-packages\sklearn\utils\validation.py", строка 84, в atleast2d_or_csr assert_all_finite(X) Файл "C:\Python27\lib\site-packages\sklearn\utils\validation.py", строка 20, в assert_all_finite поднять ValueError("массив содержит NaN или бесконечность") ValueError: массив содержит NaN или бесконечностьЧто дает? Как я могу заставить SVM хорошо работать с отсутствующими данными? Имея в виду, что отсутствующие данные отлично работают для случайных лесов и других классификаторов.
РЕДАКТИРОВАТЬ: В scikit-learn есть очень простой способ сделать это, показанный на этой странице.
(скопировано со страницы и изменено)
>>> импортировать numpy как np >>> из sklearn.preprocessing import Imputer >>> #missing_values — это значение вашего заполнителя, стратегия — если вам нужно среднее значение, медиана или мода, а ось = 0 означает, что он вычисляет вменение на основе других значений признаков для этой выборки. >>> imp = Imputer (missing_values = 'NaN', стратегия = 'среднее', ось = 0) >>> имп.фит(поезд) Imputer (ось = 0, копия = True,missing_values = 'NaN', стратегия = 'среднее', подробный = 0) >>> train_imp = imp.transform(поезд)3
Вы можете либо удалить выборки с отсутствующими признаками, либо заменить отсутствующие признаки их медианами или средними значениями по столбцам.
Самый популярный ответ здесь устарел. "Imputer" теперь "SimpleImputer". Текущий способ решения этой проблемы приведен здесь.
 Для полиномиальной функции выбрана степень 3, для других функций ядра в этом нет необходимости.
Для полиномиальной функции выбрана степень 3, для других функций ядра в этом нет необходимости.  predict(X_test)
predict(X_test)  Я надеюсь, что это помогло лучше понять машины опорных векторов, математические концепции, трюк с ядром и тему Мультиклассовая классификация с помощью SVM.
Я надеюсь, что это помогло лучше понять машины опорных векторов, математические концепции, трюк с ядром и тему Мультиклассовая классификация с помощью SVM. pyplot as plt
pyplot as plt  Я загружаю данные с помощью
Я загружаю данные с помощью 
