Содержание
Процесс подачи заявки и сроки | Школа ветеринарной медицины
Перед подачей заявления
Ознакомьтесь с минимальными вступительными требованиями, чтобы убедиться, что вы имеете право подать заявление. Мы также рекомендуем вам ознакомиться с подробным контрольным списком и инструкциями, представленными здесь, прежде чем начать процесс подачи заявки.
- Обзор предварительных требований
- Учащиеся могут подать заявку, если они выполнили 75% необходимых требований. Приблизительно три могут быть незавершенными на момент подачи заявления, и все они должны быть завершены в весеннем семестре / квартале до зачисления. Конкретные требования к курсу изложены в Курсах академической подготовки и предварительных требований.
- Возьмите GRE
- Требуется общий GRE, который включает в себя вербальные, количественные и аналитические письменные разделы. При первоначальной оценке заявки используется только количественная оценка, хотя разделы устной и письменной речи могут использоваться , если ваша заявка оценивается комплексно.

Примечание. Из соображений общественного здравоохранения ETS временно предлагает вариант Test at Home .
GRE можно сдавать столько раз, сколько вы пожелаете в течение пятилетнего периода, и мы будем использовать ваш самый высокий количественный балл для оценки вашего заявления. Сдайте или пересдайте GRE до окончательного срока GRE, 31 августа 2022 года. Никакие баллы, полученные до 31 августа 2017 года, не будут приняты для цикла подачи заявок на 2022–2023 годы.
- Определите, насколько конкурентоспособным может быть ваше приложение
- Все заявки первоначально оцениваются по трем направлениям:
1. Два средних балла: 1) последние 45 семестров/68 четвертей часа и 2) все научные курсы (см., что считается научным курсом, здесь, на веб-сайте VMCAS)
2. Количественный балл GRE
3. Три электронных рекомендательных письма (eLors)Изучив самую последнюю статистику зачисления, в частности, средний балл GPA и баллы GRE, вы можете определить, насколько конкурентоспособным может быть ваше приложение.
Примечание: Средние баллы выше для заявителей, не являющихся резидентами ЦА, поскольку для нерезидентов ЦА доступно меньше мест. Заявки нерезидентов ЦА оцениваются по трем критериям, перечисленным выше, и не включаются в процесс целостной проверки.

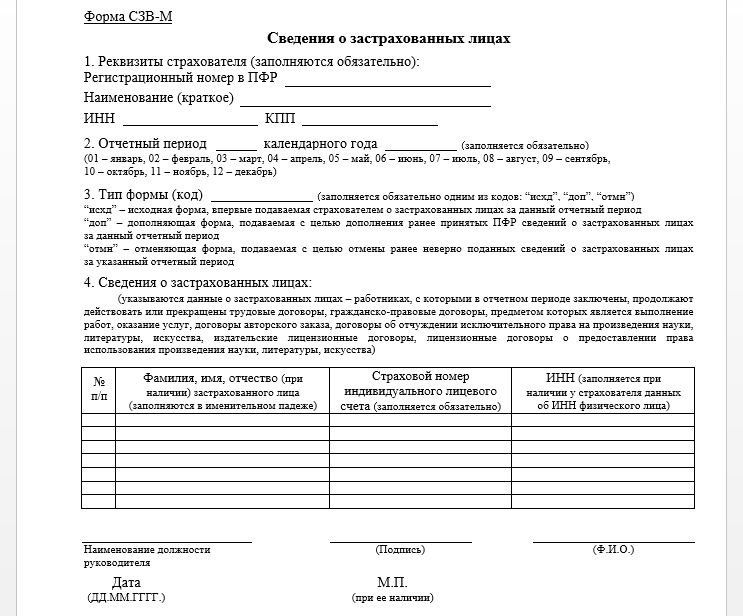 Примечание: Средние баллы выше для заявителей, не являющихся резидентами ЦА, поскольку для нерезидентов ЦА доступно меньше мест. Заявки нерезидентов ЦА оцениваются по трем критериям, перечисленным выше, и не включаются в процесс целостной проверки.
Примечание: Средние баллы выше для заявителей, не являющихся резидентами ЦА, поскольку для нерезидентов ЦА доступно меньше мест. Заявки нерезидентов ЦА оцениваются по трем критериям, перечисленным выше, и не включаются в процесс целостной проверки. Как подать заявление
Ветеринарно-медицинская служба подачи заявок (VMCAS) — это централизованная служба подачи заявок для колледжей ветеринарной медицины. Через VMCAS вы можете заполнить одну заявку и отправить все необходимые материалы через эту службу. Затем ваше заявление обрабатывается, проверяется на точность и отправляется в указанные вами ветеринарные медицинские школы.
- Шаг 1: Приложение VMCAS
Кандидаты должны подать заявку через центральную систему подачи заявок VMCAS. Бумажные приложения недоступны. Все материалы заявки, включая баллы GRE, академические справки и рекомендательные письма, ДОЛЖНЫ быть представлены через систему VMCAS.
Любые из вышеперечисленных материалов заявки, отправленные непосредственно в Калифорнийский университет в Дэвисе, не могут быть приложены к заявке или возвращены заявителям.21 января 12 мая 15 сентября Приложение VMCAS открывается Ветеринарные программы станут доступны для студентов, чтобы выбрать Заявку необходимо отправить до 20:59 (тихоокеанское время) VMCAS может принимать стенограммы и отчеты о результатах Заявки можно подавать Все остальные материалы заявки (eLors, стенограммы и т. д.) должны быть отправлены в VMCAS. Просроченные документы не принимаются. - Шаг 2: стенограммы и отчеты о результатах для VMCAS
Стенограммы
Закажите официальные стенограммы по номеру во всех учебных заведениях, которые вы посещали, и отправьте их непосредственно в VMCAS. Просмотрите отправку официальных стенограмм в VMCAS для получения подробных инструкций по всем американским, международным и зарубежным стенограммам.VMCAS должен получить все стенограммы до крайнего срока 15 сентября. Поздние стенограммы не будут получены. Любые стенограммы, случайно отправленные в Калифорнийский университет в Дэвисе, НЕ МОГУТ быть добавлены или прикреплены к приложениям. Заявки, в которых отсутствуют стенограммы к установленному сроку, не будут рассматриваться для поступления. Никаких исключений не будет, так что планируйте заранее.
GRE
31 августа 2022 г. — последний день сдачи GRE для текущего цикла подачи заявок. Используйте код школы VMCAS 4804 , чтобы ваши результаты были переданы в VMCAS. Не используйте общий код школы UC Davis. Не ждите до последней минуты, чтобы сдать GRE, так как продление срока не предоставляется . Проверьте свой портал VMCAS, чтобы убедиться, что ваши баллы GRE были получены до крайнего срока. Если крайний срок близок, а вы не видите свои результаты, свяжитесь напрямую с VMCAS и ETS.Иностранные учащиеся должны ознакомиться с требованиями к иностранным учащимся на предмет дополнительных требований VMCAS.
- Шаг 3. Отправка и мониторинг VMCAS
Все представленные заявки должны быть проверены VMCAS, , что может занять до четырех недель . Отправив все свои стенограммы ДО крайнего срока (15 сентября 2022 г.), вы значительно повысите свои шансы на досрочную проверку вашего заявления и время для внесения исправлений, если это необходимо. Дополнительные сведения см. в разделе «Отправка и мониторинг вашего приложения VMCAS».
Примечание. Заявки, получившие статус «проверено», могут оставаться незавершенными, если отсутствуют другие материалы, такие как eLors или результаты тестов. Если в вашей проверенной заявке отсутствуют какие-либо материалы заявки после крайнего срока 15 сентября, она не будет рассматриваться для приема, даже если вы подали дополнительную заявку.
- Шаг 4: Дополнительное заявление Калифорнийского университета в Дэвисе
Примерно в середине августа мы начинаем импортировать проверенные приложения из VMCAS на портал для абитуриентов Школы ветеринарной медицины Калифорнийского университета в Дэвисе. Кандидаты уведомляются по электронной почте, когда их приложение VMCAS было добавлено.
После импорта кандидатам будет отправлено электронное письмо с инструкциями по настройке их портала для кандидатов, заполнению вторичной заявки и оплате сбора за обработку в размере 60 долларов США. Вторичная заявка включает в себя личное заявление (не более 2000 символов) и выбор трех eLors, которые вы хотите, чтобы мы рассмотрели для вашей заявки. Дополнительная заявка UCD должна быть подана 15 октября.
Примечание. Мы не начинаем загружать проверенные приложения до середины июня, даже если ваше приложение было проверено до этого времени. Мы продолжим импортировать проверенные приложения один-два раза в неделю до крайнего срока 15 сентября. Дополнительные инструкции по применению могут быть отправлены по электронной почте в течение недели.
 Любые из вышеперечисленных материалов заявки, отправленные непосредственно в Калифорнийский университет в Дэвисе, не могут быть приложены к заявке или возвращены заявителям.
Любые из вышеперечисленных материалов заявки, отправленные непосредственно в Калифорнийский университет в Дэвисе, не могут быть приложены к заявке или возвращены заявителям. Просмотрите отправку официальных стенограмм в VMCAS для получения подробных инструкций по всем американским, международным и зарубежным стенограммам.
Просмотрите отправку официальных стенограмм в VMCAS для получения подробных инструкций по всем американским, международным и зарубежным стенограммам. Если крайний срок близок, а вы не видите свои результаты, свяжитесь напрямую с VMCAS и ETS.
Если крайний срок близок, а вы не видите свои результаты, свяжитесь напрямую с VMCAS и ETS.
 Дополнительные инструкции по применению могут быть отправлены по электронной почте в течение недели.
Дополнительные инструкции по применению могут быть отправлены по электронной почте в течение недели. Как оцениваются заявки
После подачи дополнительных заявок они проверяются на предмет их а) полноты и б) приемлемости. Любые заявки, в которых отсутствуют материалы заявки или не соответствующие критериям приемлемости (например, минимальный средний балл, количество часов ветеринарного опыта, один eLor от ветеринара), не будут рассматриваться для приема.
- Шаг 1: Начальный рейтинг
Все заполненные и отвечающие требованиям заявки ранжируются на основе двух средних баллов (последние 45 семестров/68 четвертей часов и все научные курсы), количественного балла GRE и объединенных сводных баллов по трем eLors.
- Шаг 2: 180 лучших кандидатов
Лучшие 180 заявителей (примерно 25% лучших заявителей CA и 10% заявителей-нерезидентов) приглашаются на собеседование.
- Шаг 3. Комплексный обзор
Следующие 180 абитуриентов (только жители Калифорнии) в порядке ранжирования (на основе вышеуказанных факторов) будут всесторонне рассмотрены Приемной комиссией Школы. Рассмотрение заявки будет включать в себя: ветеринарный и другой опыт работы с животными, исследовательские возможности, вопросы для эссе VMCAS и личное заявление UCD SVM, рекомендательные письма, лидерство и общественные работы, образование, жизненный опыт и мотивацию для ветеринарной карьеры.
Из этих 180 претендентов 60 приглашены на собеседование.
- Шаг 4: Интервью
240 соискателей приглашены на виртуальное собеседование в начале декабря посредством множественных мини-собеседований (MMI). MMI — это короткие структурированные интервью, используемые для оценки личных качеств/качеств. Более подробную информацию о процессе можно найти в разделе часто задаваемых вопросов.
Даты MMI 2022 – 1, 2, 5 и 6 декабря*. Кандидаты выбирают один из четырех дней собеседования продолжительностью около 100 минут.
Ранней весной будут проводиться дни приема студентов, чтобы студенты могли пообщаться, совершить поездку по объектам, встретиться с персоналом и преподавателями, а также узнать больше о финансовой помощи, учебной программе и других ресурсах.
Шаг 5: Решение о зачислении
По завершении собеседования в MMI все кандидаты будут ранжированы на основе их баллов MMI. Приемная комиссия собирается для обсуждения результатов MMI. Первоначальный ранжированный список лучших кандидатов на основе ожидаемого размера класса (предложение приема), а затем следующие кандидаты (в списке ожидания) будут обсуждаться с деканом. Приблизительно 150 студентам предлагается зачисление, а еще 40-45 человек получают место в списке ожидания. Зачисление будет предлагаться кандидатам исключительно на основании их рейтинга MMI.
Уведомления о принятии, отклонении и листе ожидания будут размещены на порталах кандидатов к концу января.
 Комплексный обзор
Комплексный обзор 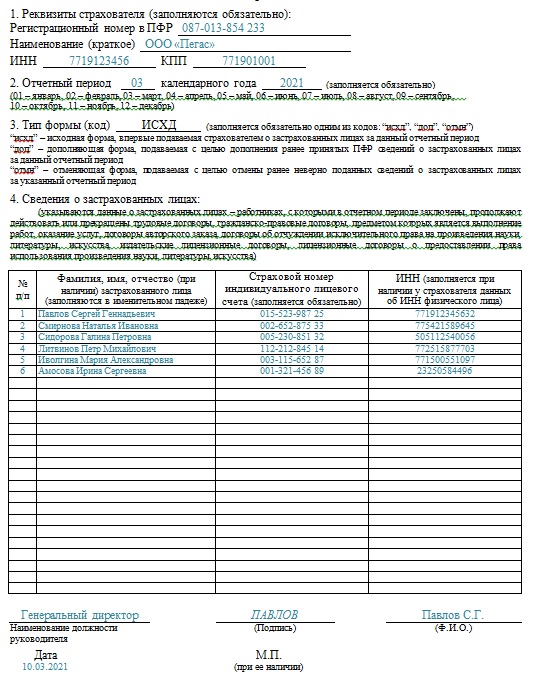 Ранней весной будут проводиться дни приема студентов, чтобы студенты могли пообщаться, совершить поездку по объектам, встретиться с персоналом и преподавателями, а также узнать больше о финансовой помощи, учебной программе и других ресурсах.
Ранней весной будут проводиться дни приема студентов, чтобы студенты могли пообщаться, совершить поездку по объектам, встретиться с персоналом и преподавателями, а также узнать больше о финансовой помощи, учебной программе и других ресурсах. 
Контактная информация VMCAS
Телефон: (617) 612-2884
Факс: (617) 612-2051
Электронная почта: [email protected]
Почтовый адрес (только для выписок): P.O. Box 9126 Watertown, MA 02471
Виртуальная информационная сессия — процесс приема
Посмотрите запись нашего виртуального информационного сеанса, чтобы увидеть подробный обзор всего процесса приема, включая то, как кандидаты оцениваются и отбираются для собеседований.
Семинар по улучшению приложений
Этот семинар был проведен 24 января 2022 г. для учащихся, заинтересованных в повторной подаче заявки на участие в программе. 90-минутный мастер-класс можно посмотреть здесь.
Метод опорных векторов
(SVM) в R: глубокое погружение
Метод опорных векторов (SVM) — это контролируемый алгоритм машинного обучения, который анализирует и классифицирует данные по одной из двух категорий, также известных как двоичный классификатор.
Что такое машинное обучение?
Способность компьютера учиться на данных без явного программирования называется машинным обучением.
Это работает следующим образом: машина учится на существующих данных и предсказывает или принимает решения относительно будущих данных. Ваш набор данных должен содержать известные результаты, чтобы машина могла учиться, брать данные и корректировать их, а также применять алгоритм машинного обучения. Алгоритм обучается, создает модель, анализирует модель, а затем использует эту модель для прогнозирования.
Существует три основных категории алгоритмов машинного обучения:
- Алгоритмы обучения под наблюдением
- Алгоритмы обучения без учителя
- Обучение с подкреплением
Обучение под наблюдением
Обучение под наблюдением относится к набору данных с известными результатами. Если он не контролируется, нет никаких известных результатов, и у вас не будет категорий или классов, необходимых для обучения машины.
Если он не контролируется, нет никаких известных результатов, и у вас не будет категорий или классов, необходимых для обучения машины.
Существует два основных типа алгоритмов машинного обучения в категории контролируемого обучения:
- Классификация (подпадает под SVM)
- Регрессия
Алгоритмы классификации
С классификацией вы прогнозируете категории во время регрессии и обычно прогнозируете значения.
В обучении с учителем классификация является многомерной в том смысле, что иногда у вас есть только два класса («да» или «нет», или «верно» или «ложно»). Но иногда их больше двух. Например, при управлении рисками или моделировании рисков у вас может быть «низкий риск», «средний риск» или «высокий риск». SVM — это бинарный классификатор (классификатор, используемый для задач классификации типа «истина/ложь», «да/нет»).
Особенности важны в обучении с учителем. Если есть несколько функций, SVM может быть лучшим выбором алгоритма классификации, в отличие от логистической регрессии. При обучении с учителем вы представляете компьютеру примерные входные данные и их желаемые выходные данные (эти известные результаты). Цель состоит в том, чтобы изучить общее правило, которое сопоставляет входные данные с выходными.
При обучении с учителем вы представляете компьютеру примерные входные данные и их желаемые выходные данные (эти известные результаты). Цель состоит в том, чтобы изучить общее правило, которое сопоставляет входные данные с выходными.
Обнаружение ошибок, отток клиентов, предсказание цены акции (не значение цены акции, а будет ли она расти или падать) и предсказание погоды (солнечно/не солнечно; дождь/нет дождя) — все это примеры.
Алгоритмы классификации обычно берут прошлые данные (данные, для которых у вас есть известные результаты), обучают модель, берут новые данные после обучения модели, принимают их и создают прогнозы (например, это грузовик или автомобиль?) .
| Изучите анализ данных, визуализацию данных, машинное обучение, глубокое обучение, SQL, R и Python с курсом Data Science с гарантией размещения. Ознакомьтесь с курсом прямо сейчас! |
Что такое SVM?
SVM — это тип алгоритма классификации, который классифицирует данные на основе их признаков. SVM классифицирует любой новый элемент в один из двух классов.
SVM классифицирует любой новый элемент в один из двух классов.
После ввода некоторых входных данных алгоритм разделит и классифицирует данные, а затем создаст выходные данные. Когда вы принимаете больше новых данных (в этом примере неизвестная переменная фруктов), алгоритм правильно классифицирует фрукты: например, «яблоко» против «апельсина».
Понимание SVM
Ниже приведены несколько примеров для более подробного понимания SVM:
Пример 1: Задача классификации линейного SVM с набором 2D-данных
Цель этого примера состоит в том, чтобы классифицировать игроков в крикет на игроков с битой или боулеров, используя соотношение ранов к калитке. Игрок с большим количеством пробежек будет считаться игроком с битой, а игрок с большим количеством калиток будет считаться боулером.
Если вы возьмете набор данных об игроках в крикет с пробегами и калитками в столбцах рядом с их именами, вы можете создать двухмерный график, показывающий четкое разделение между боулерами и игроками с битой. Здесь мы представляем набор данных с четким разделением между боулерами и игроками с битой, чтобы помочь понять SVM.
Здесь мы представляем набор данных с четким разделением между боулерами и игроками с битой, чтобы помочь понять SVM.
Прежде чем отделять что-либо с помощью математики высокого уровня, давайте посмотрим на неизвестное значение, которое представляет собой новые данные, вводимые в набор данных без предварительной классификации.
Следующим шагом является нанесение границы решения или линии, разделяющей два класса, чтобы помочь классифицировать новые точки данных.
На самом деле вы можете нарисовать несколько границ, как показано выше. Затем вам нужно найти линию наилучшего соответствия, которая четко разделяет эти две группы. Правильная линия поможет вам классифицировать новую точку данных.
Вы можете найти наилучшую линию, вычислив максимальный запас по равноудаленным опорным векторам. Опорные векторы в этом контексте просто означают две точки — по одной из каждого класса, которые находятся ближе всего друг к другу, но максимизируют расстояние между ними или границу.
Примечание. Вы можете подумать, что слово «вектор» относится к точкам данных. Хотя это может иметь место в двухмерном или трехмерном пространстве, как только вы попадаете в более высокие измерения с большим количеством функций в вашем наборе данных, вам нужно рассматривать их как векторы. Причина, по которой они являются опорными векторами, заключается в том, что два ближайших друг к другу вектора максимизируют расстояние между двумя группами, поддерживающими алгоритм.
В верхней части графика есть несколько точек, которые расположены довольно близко друг к другу, а также в нижней части графика. Ниже показаны моменты, которые вам необходимо учитывать. Остальные точки слишком далеко. Боулер указывает направо, а игрок с битой указывает налево.
Математически вы можете рассчитать расстояние между всеми этими точками и минимизировать это расстояние. Выбрав опорные векторы, нарисуйте разделительную линию, а затем измерьте расстояние от каждого опорного вектора до линии. Лучшая линия всегда будет иметь наибольший запас или расстояние между опорными векторами.
Лучшая линия всегда будет иметь наибольший запас или расстояние между опорными векторами.
Например, если вы считаете желтую линию границей принятия решения, игрок с новой точкой данных будет игроком в боулер. Но, поскольку поля не кажутся максимальными, вы можете придумать лучшую линию.
Используйте другие опорные векторы, проведите между ними границу решения, а затем рассчитайте запас. Обратите внимание, что неизвестная точка данных будет считаться игроком с битой.
Продолжайте делать это, пока не найдете правильную границу решения с наибольшим запасом.
Если вы посмотрите на зеленую границу решения, то увидите, что линия имеет максимальный запас по сравнению с двумя другими. Это граница наибольшего запаса, и когда вы классифицируете неизвестное значение данных, вы можете видеть, что оно явно принадлежит классу игрока с битой. Зеленая линия идеально разделяет данные, потому что она имеет максимальный запас между опорными векторами. На данный момент вы можете быть уверены в классификации — новая точка данных действительно является игроком с битой.
На данный момент вы можете быть уверены в классификации — новая точка данных действительно является игроком с битой.
Технически эта разделительная линия называется гиперплоскостью. В двухмерных пространствах мы обычно называем разделительные линии «линиями», но в трехмерных и более высоких измерениях они считаются «плоскостями» или «гиперплоскостями». Технически все они гиперпланы.
Искомая гиперплоскость с максимальным расстоянием от опорных векторов. Иногда ее называют положительной гиперплоскостью (D+), это кратчайшее расстояние до ближайшей положительной точки и (D-) или отрицательной гиперплоскостью, которая является кратчайшим расстоянием до ближайшей отрицательной точки.
Сумма (D+) и (D-) называется запасом расстояния. Вы всегда должны стараться максимизировать запас по расстоянию, чтобы избежать ошибочной классификации. Например, вы можете видеть, что желтое поле намного меньше зеленого поля.
Этот набор задач является двумерным, поскольку классификация проводится только между двумя классами. Он называется линейным SVM.
Он называется линейным SVM.
Пример 2: Понимание ядра SVM. Проблема классификации с данными более высокой размерности
Набор данных, показанный ниже, не имеет четкого линейного разделения между двумя классами. На языке машинного обучения вы бы сказали, что они не являются линейно разделимыми. Как заставить машину опорных векторов работать с такими данными?
Поскольку вы не можете разделить его на два класса с помощью линии, вам необходимо преобразовать его в более высокое измерение, используя функцию ядра для набора данных.
Более высокое измерение позволяет четко разделить две группы плоскостью. Здесь вы можете нарисовать несколько плоскостей между зелеными и красными точками — с конечной целью максимизировать поля.
Если вы укажете R=число измерений, функция ядра преобразует двумерное пространство (R2) в трехмерное пространство (R3). Как только данные разделены на три измерения, вы можете применить SVM и разделить две группы с помощью двумерной плоскости.
Аналогично в более высоких измерениях (3+D):
Существует множество типов функций ядра, например:
- Ядро Гаусса RBF
- Сигмовидное ядро
- Полиномиальное ядро
В зависимости от размеров и способа преобразования данных вы можете выбрать любую из этих функций ядра.
Пример использования: классификация лошадей и мулов с помощью SVM
Давайте обсудим вариант использования, когда мы используем SVM для классификации новых данных как лошадей или мулов.
Постановка задачи: классифицируйте лошадей и мулов, используя рост и вес как два признака. Лошади и мулы обычно имеют разный вес и рост, причем лошади тяжелее и выше.
Ниже приведены шаги для классификации:
- Импорт набора данных
- Убедитесь, что у вас есть библиотеки. В библиотеку e1071 встроены алгоритмы SVM. Создайте опорные векторы, используя библиотеку.
- После того, как данные используются для обучения графика алгоритма, гиперплоскость получает визуальное представление о том, как данные разделены. Если данные двумерные или трехмерные, их будет легче построить.
- Использовать обученную модель для классификации новых значений. У нас должен быть обучающий набор и тестовый набор. Затем введите новые данные. В нашем примере мы собираемся использовать весь набор данных для обучения алгоритма, а затем посмотрим, как он работает.
- Как только вы увидите, как он работает, алгоритм решит, является ли изображение лошадью или мулом.

Вот код R:
Реальные приложения SVM
SVM использует алгоритмы обучения с учителем для выполнения классификации. Это мощный метод классификации неструктурированных данных, создания надежных прогнозов и сокращения избыточной информации.
Более того, SVM имеет приложения в различных сферах повседневной жизни, например:
Распознавание лиц
Используя данные обучения изображений, SVM классифицирует пиксели на изображениях, например лица или не лица
Текстовая классификация
Данные обучения используются для классификации различных типов документов. Например, новостные статьи можно классифицировать как «деловые» или «развлекательные».
Классификация изображений
Классифицируя изображения с помощью улучшенных методов, SVM повышает точность поиска.
Биоинформатика
Алгоритмы SVM повысили эффективность обнаружения гомологии белков, классификации рака, классификации генов и т. д.
.
Заключение
После такого глубокого погружения в SVM стоит сделать резервную копию, чтобы взглянуть на общую картину — наука о данных уже широко распространена в нашей повседневной жизни, и в будущем она станет еще более распространенной. Кроме того, сейчас это одна из самых популярных и прибыльных профессий. Наверняка, если вы нашли время, чтобы прочитать эту статью, у вас есть некоторый интерес. Независимо от того, являетесь ли вы новичком или хотите вывести свою карьеру на новый уровень, профессионально разработанные программы Simplilearn помогут вам получить все, что вам нужно знать об этой многообещающей области.