Содержание
Новости
Нашли ошибку в тексте? Выделите мышкой текст и нажмите эту ссылку
Календарь
Подробный календарь Подразделы
|
[ Показать/скрыть поиск/фильтр ] 31. Протокол №2 от 23.12.2022 |
 12.2022 12:42 (просмотров: 82)
12.2022 12:42 (просмотров: 82) Во все стадии работ по капремонту будут вовлекать родителей, учеников и учителей, сказал секретарь Генсовета «Единой России» Андрей Турчак на совещании по реализации программы капремонта школ с Минпросвещения.
Во все стадии работ по капремонту будут вовлекать родителей, учеников и учителей, сказал секретарь Генсовета «Единой России» Андрей Турчак на совещании по реализации программы капремонта школ с Минпросвещения. Высокий, неотложная помощь, фильтр-бокс, прививочный кабинет, процедурный кабинет) будут работать 2 и 6 января с 08:00 до 17:00, 4 января – в режиме рабочей субботы с 08:00 до 13:00.
Высокий, неотложная помощь, фильтр-бокс, прививочный кабинет, процедурный кабинет) будут работать 2 и 6 января с 08:00 до 17:00, 4 января – в режиме рабочей субботы с 08:00 до 13:00.Машина опорных векторов
Метод опорных векторов
Метод опорных векторов (SVM) — это контролируемый метод классификации, основанный на теории статистического обучения, который часто дает хорошие результаты классификации сложных и зашумленных данных. Дополнительные сведения см. в разделе Фон машины опорных векторов.
Дополнительные сведения см. в разделе Фон машины опорных векторов.
Примечание. Классификация SVM может занять несколько часов, чтобы выполнить обучающие данные, в которых используются большие области интереса (ROI).
- Используйте инструмент ROI, чтобы определить области обучения для каждого класса. Чем больше пикселей и классов, тем лучше будут результаты.
- Используйте инструмент ROI Tool, чтобы сохранить ROI в файле .roi.
- Отобразите входное изображение, которое вы будете использовать для классификации SVM, вместе с файлом ROI.
- На панели инструментов выберите Классификация > Классификация с учителем > Классификация машины опорных векторов . Появится диалоговое окно «Входной файл классификации».
- Выберите входной файл и выполните дополнительные пространственные и спектральные поднастройки, затем нажмите ОК .
 Появится диалоговое окно «Параметры классификации машины опорных векторов».
Появится диалоговое окно «Параметры классификации машины опорных векторов». - В списке Select Classes from Regions выберите как минимум один ROI и/или вектор в качестве обучающих классов. Перечисленные ROI получены из доступных ROI в диалоговом окне ROI Tool. Перечисленные векторы получены из открытых векторов в списке доступных векторов.
- Выберите тип ядра для использования в классификаторе SVM из раскрывающегося списка. Вариантов Линейная , Полиномиальная , Радиальная базисная функция и Сигмовидная . В зависимости от выбранного варианта могут появиться дополнительные поля.
- Если тип ядра равен Polynomial , установите Degree of Kernel Polynomial , чтобы указать степень использования для классификации SVM. Минимальное значение — 1, значение по умолчанию — 2, максимальное значение — 6.
- Если тип ядра — это полином или сигмоид , укажите смещение в функции ядра , которое ядро будет использовать в алгоритме SVM. По умолчанию 1.
- Если тип ядра Polynomial , Radial Basis Function или Sigmoid , используйте поле Gamma in Kernel Function для установки параметра гаммы, используемого в функции ядра. Это значение с плавающей запятой больше или равно 0,01. По умолчанию это обратное количество каналов во входном изображении.
- Укажите параметр штрафа для использования алгоритмом SVM. Это значение с плавающей запятой больше или равно 0,01. Параметр штрафа управляет компромиссом между допустимыми ошибками обучения и установлением жестких границ. Увеличение значения параметра штрафа увеличивает стоимость неправильной классификации баллов и заставляет ENVI создавать более точную модель, которая может плохо обобщать. По умолчанию 100.
- Используйте 9Поле 0005 Pyramid Levels для установки количества иерархических уровней обработки, которые будут применяться в процессе обучения и классификации SVM. Если это значение равно 0, ENVI обрабатывает изображение только с полным разрешением. Значение по умолчанию — 0. Максимальное значение — динамическое; оно зависит от размера выбранного вами изображения. Максимальное значение определяется критерием того, что размер самого высокого изображения пирамидного уровня превышает 64 x 64. Например, для изображения размером 24 000 x 24 000 максимальный уровень равен 8.
- Если значение поля Pyramid Levels больше нуля, установите пороговое значение переклассификации Pyramid , чтобы указать порог вероятности, которому должен соответствовать пиксель, классифицированный на более низком уровне разрешения, чтобы избежать повторной классификации с более высоким разрешением. Диапазон значений — от 0 до 1. Значение по умолчанию — 0,9.
- Используйте поле Classification Probability Threshold , чтобы установить вероятность, которая требуется классификатору SVM для классификации пикселя. Пиксели, в которых вероятности всех правил меньше этого порога, не классифицируются. Диапазон значений от 0 до 1. Значение по умолчанию — 0,0.
- Выберите вывод классификации в Файл или Память .
- Использовать изображения правил вывода ? переключатель, чтобы выбрать, создавать ли изображения правила вывода. Используйте изображения правил для создания промежуточных результатов изображений классификации перед окончательным назначением классов. Позже вы можете использовать изображения правил в классификаторе правил для создания нового изображения классификации без необходимости пересчета всей классификации.
- Если вы выбрали Да для вывода изображений правил, выберите вывод в Файл или Память .
- Щелкните OK . ENVI добавляет полученный результат в Layer Manager. Если вы выбрали вывод изображений правил, ENVI создает изображения правил для каждого класса со значениями пикселей, равными проценту (0-100%) каналов, которые соответствуют этому классу. Области, удовлетворяющие минимальному порогу, переносятся как классифицированные области в классифицированное изображение.
 Появится диалоговое окно «Параметры классификации машины опорных векторов».
Появится диалоговое окно «Параметры классификации машины опорных векторов». По умолчанию 1.
По умолчанию 1. Если это значение равно 0, ENVI обрабатывает изображение только с полным разрешением. Значение по умолчанию — 0. Максимальное значение — динамическое; оно зависит от размера выбранного вами изображения. Максимальное значение определяется критерием того, что размер самого высокого изображения пирамидного уровня превышает 64 x 64. Например, для изображения размером 24 000 x 24 000 максимальный уровень равен 8.
Если это значение равно 0, ENVI обрабатывает изображение только с полным разрешением. Значение по умолчанию — 0. Максимальное значение — динамическое; оно зависит от размера выбранного вами изображения. Максимальное значение определяется критерием того, что размер самого высокого изображения пирамидного уровня превышает 64 x 64. Например, для изображения размером 24 000 x 24 000 максимальный уровень равен 8. Пиксели, в которых вероятности всех правил меньше этого порога, не классифицируются. Диапазон значений от 0 до 1. Значение по умолчанию — 0,0.
Пиксели, в которых вероятности всех правил меньше этого порога, не классифицируются. Диапазон значений от 0 до 1. Значение по умолчанию — 0,0. Области, удовлетворяющие минимальному порогу, переносятся как классифицированные области в классифицированное изображение.
Области, удовлетворяющие минимальному порогу, переносятся как классифицированные области в классифицированное изображение.Фон машины опорных векторов, Фон машины опорных векторов в извлечении признаков
Реализация метода опорных векторов с помощью Scikit-Learn
В этом руководстве мы рассмотрим:
- Введение в алгоритм метода опорных векторов
- Реализация SVM с использованием Python и Sklearn
Итак, приступим!
Воплотите этот проект в жизнь
Работа по градиенту
Введение в метод опорных векторов
Метод опорных векторов (SVM) — это контролируемый алгоритм машинного обучения, который можно использовать как для задач классификации, так и для задач регрессии. SVM очень хорошо работает даже с ограниченным объемом данных.
В этом посте мы узнаем о машине опорных векторов для классификации. Давайте сначала рассмотрим некоторые из общих случаев использования алгоритма машины опорных векторов.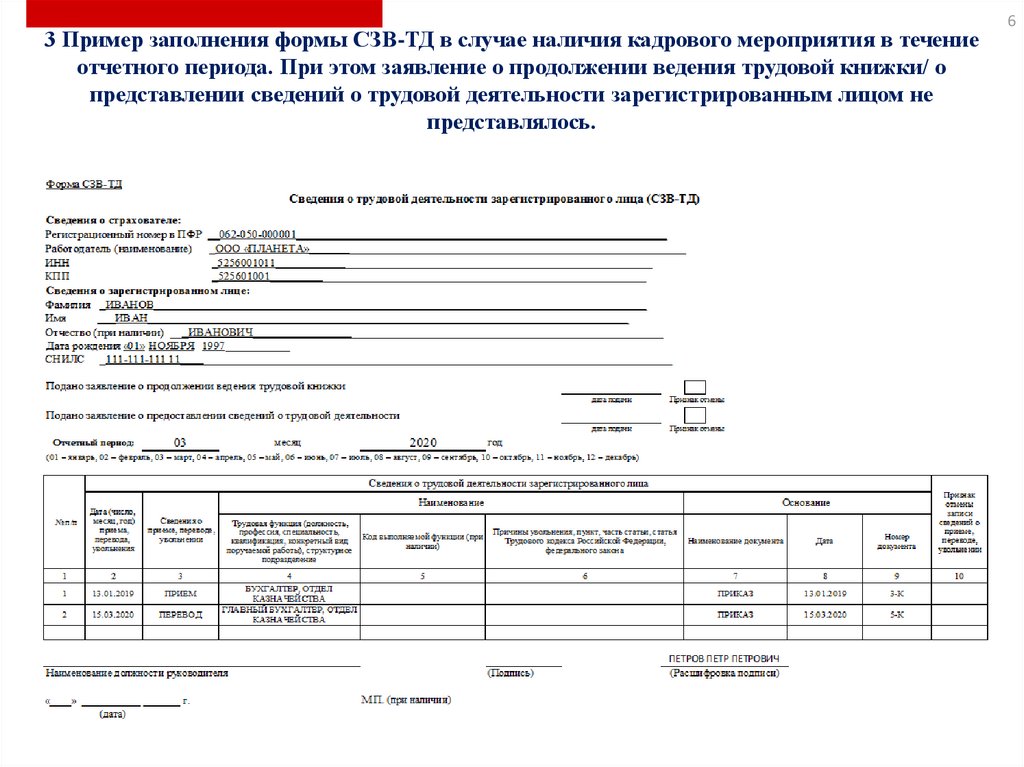
Варианты использования
Классификация болезней: Например, если у нас есть данные о пациентах с таким заболеванием, как диабет, мы можем предсказать, будет ли у нового пациента диабет или нет.
Классификация текста: Сначала нам нужно преобразовать текст в векторное представление. Затем мы можем применить алгоритм машины опорных векторов к закодированному тексту, чтобы отнести его к определенному классу.
Классификация изображений: Изображения преобразуются в вектор, содержащий значения пикселей, затем SVM присваивает метку класса.
Давайте теперь разберемся с некоторыми ключевыми терминами, связанными с SVM.
Ключевые термины
Источник: Оскар Контрерас Карраско
Опорный вектор : Опорные векторы — это точки данных, расположенные ближе к гиперплоскости, как показано на изображении выше. Используя опорные векторы, алгоритм максимизирует запас или разделение между классами. При изменении опорных векторов изменится и положение гиперплоскости.
При изменении опорных векторов изменится и положение гиперплоскости.
Гиперплоскость: Гиперплоскость в двух измерениях — это просто линия, которая лучше всего разделяет данные. Эта линия является границей решения между классами, как показано на изображении выше. Для трехмерного распределения данных гиперплоскость будет двумерной поверхностью, а не линией.
Поле: Это расстояние между каждым из опорных векторов, как показано выше. Алгоритм направлен на максимизацию маржи. Проблема нахождения максимального запаса (и, следовательно, лучшей гиперплоскости) является задачей оптимизации и может быть решена с помощью методов оптимизации.
Ядро: Ядро — это тип функции, которая применяется к точкам данных для отображения исходных нелинейных точек данных в многомерное пространство, где они являются разделимыми. Во многих случаях не будет линейной границы решения, что означает, что ни одна прямая линия не разделит оба класса. Ядра решают эту проблему. Существует множество доступных функций ядра. ядро RBF (радиальная базисная функция) обычно используется для задач классификации.
Ядра решают эту проблему. Существует множество доступных функций ядра. ядро RBF (радиальная базисная функция) обычно используется для задач классификации.
Разобравшись с этими ключевыми терминами, давайте углубимся в изучение данных.
Исследовательский анализ данных
Сначала мы импортируем необходимые библиотеки. Мы импортируем numpy , pandas и matplotlib . Кроме того, нам также нужно импортировать SVM из sklearn.svm .
Мы также будем использовать train_test_split из sklearn.model_selection и precision_score из sklearn.metrics . Мы будем использовать matplotlib.pyplot для визуализации.
импортировать numpy как np импортировать панд как pd из sklearn.model_selection импорта train_test_split из sklearn.svm импортировать SVC из sklearn.metrics импорта precision_score import matplotlib.pyplot as plt
После импорта библиотек нам нужно прочитать данные из файла CSV во фрейм данных Pandas. Давайте проверим первые 10 строк данных.
Давайте проверим первые 10 строк данных.
Данные представляют собой набор данных о пациентах, проверенных на наличие потенциального диабета. Для простоты мы рассматриваем две характеристики возраста и уровня глюкозы и одну целевую переменную, которая является бинарной. Значение 1 указывает на диабет, а 0 указывает на отсутствие диабета.
df = pd.read_csv('SVM-Classification-Data.csv')
df.head() Данные классификации машины опорных векторов
Чтобы получить больше информации о данных, мы построили гистограмму данных, как показано ниже. Столбчатая диаграмма — это диаграмма, которая представляет категориальные данные в виде прямоугольных столбцов с высотой, представляющей имеющиеся у них значения. Гистограммы могут быть построены вертикально или горизонтально.
График ниже представляет собой вертикальную диаграмму между столбцами Возраст и Глюкоза.
Столбчатая диаграмма
Чтобы лучше понять выбросы, мы также можем посмотреть на точечную диаграмму. Ниже приведен график рассеяния признаков, присутствующих в данных.
После изучения данных мы можем выполнить некоторые из задач предварительной обработки данных, как показано ниже.
Предварительная обработка данных:
Перед подачей данных в модель классификации опорных векторов нам необходимо выполнить некоторую предварительную обработку.
Здесь мы собираемся создать две переменные x и y. x представляет функции модели, а y представляет метку модели. Мы создадим переменные x и y, взяв их из набора данных и используя train_test_split 9.0173 функция sklearn для разделения данных на обучающие и тестовые наборы.
х = df.drop('диабет',ось=1)
y = df['диабет']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0,25, random_state=42) Обратите внимание, что размер теста 0,25 означает, что мы использовали 25% данных для тестирования. random_state обеспечивает воспроизводимость. На выходе train_test_split мы получаем x_train , x_test , y_train и 9. 0172 y_test значения. Мы собираемся использовать x_train и y_train для обучения модели, а затем мы будем использовать x_test и y_test вместе для тестирования модели.
0172 y_test значения. Мы собираемся использовать x_train и y_train для обучения модели, а затем мы будем использовать x_test и y_test вместе для тестирования модели.
После завершения предварительной обработки данных пришло время определить и подогнать модель.
Определение и подбор модели
Мы создадим переменную модели и создадим экземпляр класса SVC. После этого мы будем обучать модель, но перед этим давайте обсудим некоторые важные параметры модели классификатора опорных векторов, перечисленные ниже.
Ядро : Ядро относится к классу алгоритмов для анализа образов. Это строковый параметр, который не является обязательным. Значение по умолчанию — RBF. Популярными возможными значениями являются «линейный», «полигональный», «rbf», «сигмоидальный», «предварительно вычисленный».
Linear Kernel — одно из наиболее часто используемых ядер.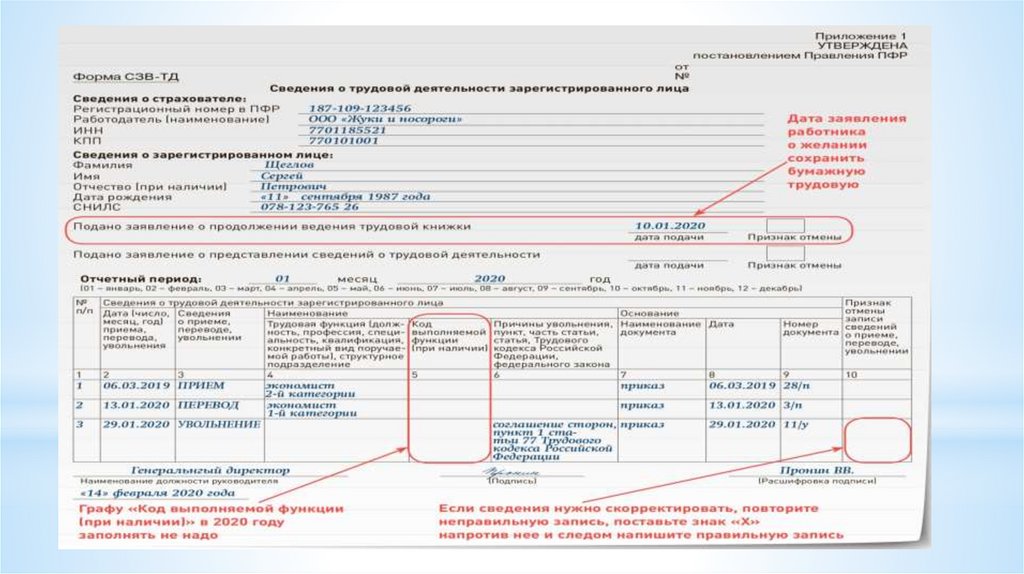 Это используется, когда данные являются линейно разделимыми, что означает, что данные могут быть разделены с помощью одной строки.
Это используется, когда данные являются линейно разделимыми, что означает, что данные могут быть разделены с помощью одной строки.
Ядро RBF используется, когда данные не являются линейно разделимыми. Ядро RBF машины опорных векторов создает нелинейные комбинации заданных функций и преобразует заданные выборки данных в пространство признаков более высокого измерения, где мы можем использовать линейную границу решения для разделения классов.
Регуляризация C : C — параметр регуляризации. Регуляризация обратно пропорциональна C. Она должна быть положительной.
Степень : Степень — это степень полиномиальной функции ядра. Он игнорируется всеми другими ядрами, такими как linear.
V erbos e : Это включает подробный вывод. Verbose — это общий термин программирования для создания большей части выходных данных журнала. Многословие означает, что программа постоянно просит рассказать все о том, что она делает.
Многословие означает, что программа постоянно просит рассказать все о том, что она делает.
Random_State: random_state — это начальное число, используемое генератором случайных чисел. Это используется для обеспечения воспроизводимости. Другими словами, для получения детерминированного поведения во время подбора необходимо зафиксировать random_state .
SupportVectorClassModel = SVC() SupportVectorClassModel.fit(x_train,y_train)
После того, как мы определили модель выше, нам нужно обучить модель, используя предоставленные данные. Для этого мы используем fit() как показано выше. Этому методу передаются два параметра, которые представляют интерес для нас (в данном случае возраст и уровень глюкозы, а также часть набора данных для обучения диабету).
После того, как модель будет правильно обучена, она выведет экземпляр SVC, как показано в выходных данных ячейки ниже.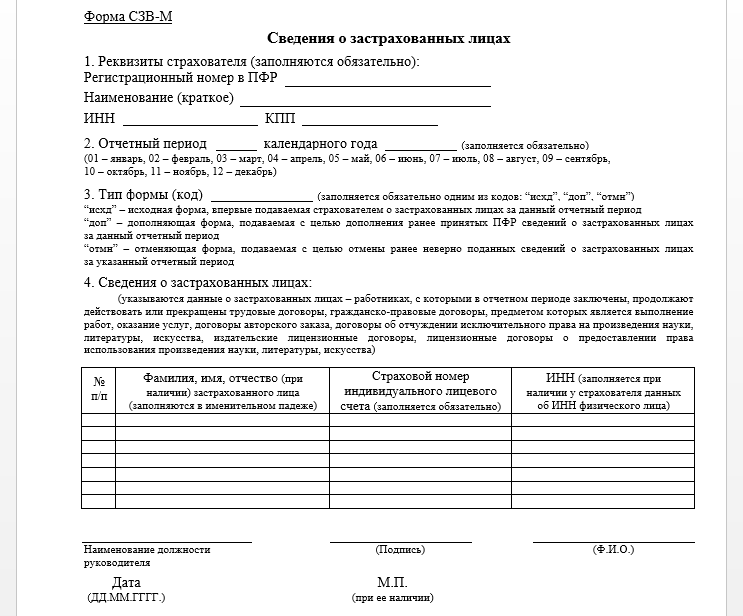
Завершение обучения модели автоматически приведет к тому, что вы опробуете некоторые прогнозы.
Прогнозирование с использованием модели
После обучения модели она готова делать прогнозы. Мы можем использовать предсказать метод в модели и передать x_test в качестве параметра, чтобы получить вывод как y_pred .
Обратите внимание, что выходные данные предсказания представляют собой массив действительных чисел, соответствующий входному массиву.
y_pred = SupportVectorClassModel.predict(x_test)
Машинное предсказание опорных векторов
После того, как предсказание сделано, естественно, мы хотели бы проверить точность модели.
Оценка модели
Теперь пришло время проверить, насколько хорошо наша модель работает на тестовых данных. Для этого мы оцениваем нашу модель, определяя точность, создаваемую моделью.
Мы собираемся использовать функцию precision_score и передадим ей два параметра y_test и y_pred.