Содержание
МАШИН ОПОРНЫХ ВЕКТОРОВ (SVM). Введение: Все, что вам нужно знать… | Аджай Ядав
Машина опорных векторов, возможно, является одним из самых популярных и обсуждаемых алгоритмов машинного обучения. Они были чрезвычайно популярны в то время, когда они были разработаны в 1990-х годах, и по-прежнему остаются популярным методом высокопроизводительного алгоритма небольшой тюнинг. В этом блоге мы будем отображать различные концепции SVC.
Сопоставленные понятия:
1. Что такое SVM?
2. Идеология SVM.
3.Развитие интуиции.
4. Терминология, используемая в SVM.
5. Гиперплоскость (поверхность решения).
6. SVM с жесткой маржой.
7. Мягкая маржа SVM.
8. Интерпретация функции потерь SVM.
9. Двойная форма SVM.
Двойная форма SVM.
10. Что такое трюк ядра?
11.Типы ядер.
12. Плюсы и минусы SVM.
13. Подготовка данных для SVM.
14. Приложение модели
Метод опорных векторов, так называемый SVM, представляет собой алгоритм обучения с учителем , который можно использовать для задач классификации и регрессии, таких как классификация опорных векторов (SVC) и регрессия опорных векторов. (СВР). Он используется для небольших наборов данных, так как обработка занимает слишком много времени. В этом наборе мы сосредоточимся на SVC.
SVM основан на идее поиска гиперплоскости, которая лучше всего разделяет объекты на разные домены.
Рассмотрим следующую ситуацию:
Есть преследователь, который отправляет вам электронные письма, и теперь вы хотите разработать функцию (гиперплоскость), которая четко различает два случая, так что всякий раз, когда вы получаете электронное письмо от сталкера, оно будет классифицировать как спам. Ниже приведены два случая, в которых нарисована гиперплоскость, какой из них вы выберете и почему? найдите минутку, чтобы проанализировать ситуацию ……
Ниже приведены два случая, в которых нарисована гиперплоскость, какой из них вы выберете и почему? найдите минутку, чтобы проанализировать ситуацию ……
Думаю, вы бы выбрали фигу(а). Вы думали, почему вы выбрали инжир(а)? Потому что электронные письма на рис. (а) четко классифицированы, и вы более уверены в этом по сравнению с рис. (б). По сути, SVM состоит из идеи создания Оптимальной гиперплоскости , которая будет четко классифицировать различные классы (в данном случае это бинарные классы).
Точки, ближайшие к гиперплоскости, называются точками опорного вектора и расстояние векторов от гиперплоскости называются полями .
Основная интуиция, которую следует развить здесь, заключается в том, что чем дальше точки SV от гиперплоскости, тем выше вероятность правильной классификации точек в соответствующих областях или классах. Точки SV очень важны при определении гиперплоскости, потому что, если положение векторов изменяется, положение гиперплоскости изменяется. Технически эту гиперплоскость также можно назвать гиперплоскость, максимизирующая запас .
Технически эту гиперплоскость также можно назвать гиперплоскость, максимизирующая запас .
Так долго в этом посте мы обсуждали гиперплоскость, давайте обоснуем ее значение, прежде чем двигаться дальше. Гиперплоскость — это функция, которая используется для различения объектов. В 2D функция, используемая для классификации объектов, представляет собой линию, тогда как функция, используемая для классификации объектов в 3D, называется плоскостью, аналогично функции, которая классифицирует точку в более высоком измерении, называется гиперплоскостью. Теперь, когда вы знаете о гиперплоскости, давайте вернемся к SVM.
Предположим, что есть измерения «m»:
таким образом, уравнение гиперплоскости в измерении «M» может быть задано как =
где,
Wi = vectors(W0,W1,W2,W3……Wm )
b = смещенный член (W0)
X = переменные.
Теперь,
Предположим, что есть 3 гиперплоскости, а именно (π, π+, π−), такие, что ‘π+’ параллельна ‘π’, проходящей через опорные векторы с положительной стороны, а ‘π-‘ параллельна ‘ π’, проходящий через опорные векторы с отрицательной стороны.
уравнения каждой гиперплоскости можно рассматривать как:
для точки X1 :
Объяснение: когда точка X1, мы можем сказать, что точка лежит на гиперплоскости, и уравнение определяет, что произведение нашего фактического выхода и уравнение гиперплоскости равно 1, что означает, что точка правильно классифицирована в положительной области.
для точки X3:
Объяснение: когда точка X3, мы можем сказать, что точка находится вдали от гиперплоскости, и уравнение определяет, что произведение нашего фактического выхода и уравнения гиперплоскости больше 1, что означает, что точка правильно классифицированы в положительной области.
для точки X4:
Объяснение: когда точка X4, мы можем сказать, что точка лежит на гиперплоскости в отрицательной области, и уравнение определяет, что произведение нашего фактического выхода и уравнения гиперплоскости равно 1, что означает, что точка правильно классифицирована в отрицательной области.
для точки X6 :
Объяснение: когда точка X6, мы можем сказать, что точка находится вдали от гиперплоскости в отрицательной области, и уравнение определяет, что произведение нашего фактического выхода и уравнения гиперплоскости больше 1, что означает, что точка правильно классифицирована в отрицательной области.
Рассмотрим ограничения, которые не классифицированы:
для точки X7:
Пояснение: При Xi = 7 точка классифицируется неправильно, так как для точки 7 wT + b будет меньше единицы, а это нарушает ограничения. Итак, мы обнаружили неправильную классификацию из-за нарушения ограничений. Точно так же мы можем также сказать для точек Xi = 8.
Таким образом, из приведенных выше примеров мы можем заключить, что для любой точки Xi
, если yi (wt*xi +b) ≥ 1:
Тогда XI правильно классифицируется
Иначе:
XI. Неверно классифицируется.
Неверно классифицируется.
Таким образом, мы видим, что если точки линейно разделимы, то только наша гиперплоскость может различать их, а если вводится какой-либо выброс, то она не может их разделить. Таким образом, этот тип SVM называется как жесткая маржа SVM 9.0009 (поскольку у нас очень строгие ограничения для правильной классификации каждой точки данных).
Мы в основном считаем, что данные линейно разделимы, и это может быть не так в реальном сценарии. Нам нужно обновление, чтобы наша функция могла пропускать несколько выбросов и иметь возможность классифицировать почти линейно отделимые точки. По этой причине мы вводим новую переменную Slack ( ξ ), которая называется Xi.
Если мы введем ξ в наше предыдущее уравнение, мы можем переписать его как
Введение Xi
если ξi= 0,
точки можно считать правильно классифицированными.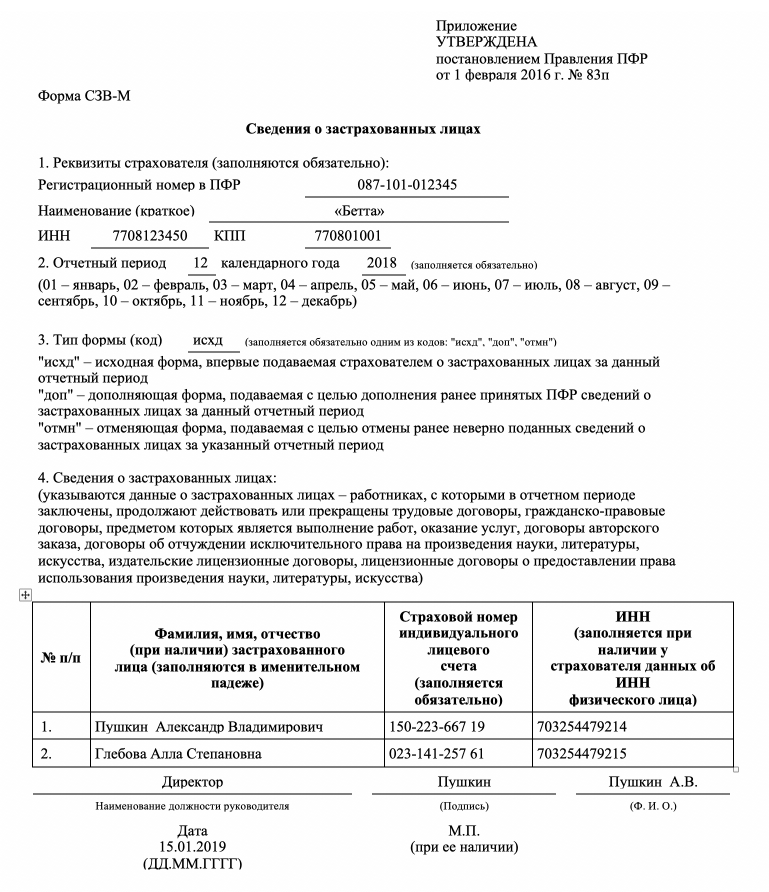
еще:
ξi> 0 , Неправильно классифицированные точки.
, поэтому, если ξi> 0, это означает, что Xi(переменная) находится в неправильном измерении, поэтому мы можем думать о ξi как об ошибке, связанной с Xi(переменной). Средняя ошибка может быть задана как;
средняя ошибка
Таким образом, наша цель математически может быть описана как;
, где ξi = ςi
ЧТЕНИЕ: Найти вектор w и скаляр b так, чтобы гиперплоскость, представленная w и b, максимизировала предельное расстояние и минимизировала член потерь при условии, что все точки указаны правильно. классифицировано.
Эта формулировка называется методом мягких границ.
, когда Zi ≥ 1, потери равны 0, когда Zi < 1, потери увеличиваются.
, таким образом, можно интерпретировать, что потери шарнира равны max(0,1-Zi).
Теперь давайте рассмотрим случай, когда наш набор данных вообще не является линейно разделимым.
По сути, мы можем отделить каждую точку данных, проецируя ее в более высокое измерение, добавляя к ней соответствующие функции, как мы делаем в логистической регрессии. Но с SVM есть мощный способ выполнить эту задачу проецирования данных в более высокое измерение. Обсуждаемый выше состав представлял собой первичную форму SVM 9.0009 . Альтернативный метод представляет собой двойную форму SVM, в которой используется множитель Лагранжа для решения задачи оптимизации ограничений.
Примечание:
Если αi>0, то Xi является опорным вектором, а когда αi=0, то Xi не является опорным вектором.
Наблюдение:
- Для решения реальной задачи нам не требуется фактическая точка данных, вместо этого может быть достаточно скалярного произведения между каждой парой вектора.
- Для вычисления константы со смещением «b» нам требуется только скалярное произведение.

- Основное преимущество двойной формы SVM по сравнению с формулировкой Лагранжа состоит в том, что она зависит только от α .

Переходя к основной части SVM, которой она наиболее известна, трюк с ядром . Ядро — это способ вычисления скалярного произведения двух векторов x и y в некотором (очень многомерном) пространстве признаков, поэтому функции ядра иногда называют «обобщенным скалярным произведением».
попробуйте прочитать это уравнение…s.t = подвергнуто
Применение трюка с ядром означает просто замену скалярного произведения двух векторов функцией ядра.
- линейное ядро
- полиномиальное ядро
- Ядро радиальной базисной функции (RBF)/гауссово ядро
Мы сосредоточимся на полиноме и гауссовском ядре, поскольку они наиболее часто используются.
Ядро полинома:
Обычно ядро полинома определяется как ;
b = степень ядра & a = постоянный член. 9т и Зб.
9т и Зб.
Метод 1:
Традиционно мы решили бы это с помощью:
, что заняло бы много времени, так как нам пришлось бы выполнять скалярное произведение для каждой точки данных, а затем вычислять скалярное произведение, которое нам может понадобиться для умножения. Представьте, что мы делаем это для тысяча точек данных….
Или же мы могли бы просто использовать
Метод 2:
с использованием трюка ядра:
В этом методе мы можем просто вычислить скалярное произведение, увеличив значение мощности. Просто не правда ли?
Ядро радиальной базисной функции (RBF)/ Гауссово ядро:
Гауссовская RBF (радиальная базисная функция) — еще один популярный метод ядра, используемый в моделях SVM для получения дополнительной информации. Ядро РБФ представляет собой функцию, значение которой зависит от расстояния от начала координат или от некоторой точки. Gaussian Kernel имеет следующий формат;
||Х1 — Х2 || = Евклидово расстояние между X1 и X2
Используя расстояние в исходном пространстве, мы вычисляем скалярное произведение (сходство) X1 и X2.
Примечание: сходство — это угловое расстояние между двумя точками.
Параметры:
- C: Инверсия силы регуляризации.
Поведение: По мере увеличения значения «c» модель получает переобучение.
По мере уменьшения значения c модель не соответствует.
2. γ : Гамма (используется только для ядра RBF)
Поведение: По мере увеличения значения « γ » модель получает переоснащение.
По мере уменьшения значения ‘ γ ’ модель не соответствует.
Плюсы:
- Действительно эффективен в высшем измерении.
- Эффективно, когда количество функций превышает число обучающих примеров.
- Лучший алгоритм, когда классы являются разделимыми
- На гиперплоскость влияют только опорные векторы, поэтому выбросы оказывают меньшее влияние.
- SVM подходит для экстремальной бинарной классификации.
минусы:
- Для обработки больших наборов данных требуется много времени.
- Плохо работает в случае перекрытия классов.
- Правильный выбор гиперпараметров SVM, обеспечивающих достаточную производительность обобщения.
- Выбор подходящей функции ядра может оказаться сложной задачей.

1. Числовое преобразование:
SVM предполагает, что ваши входные данные являются числовыми, а не категориальными. Таким образом, вы можете преобразовать их, используя один из наиболее часто используемых « один горячий кодировщик г, этикетка-кодировка и т.д. ».
2. Двоичное преобразование:
Поскольку SVM может классифицировать только двоичные данные, вам потребуется преобразовать многомерный набор данных в двоичную форму, используя метод ( один против остальных / метод «один против одного» ) метод преобразования.
Поскольку этот пост уже слишком длинный, я подумал о том, чтобы связать часть кода с моей учетной записью Github ( здесь ).
Харшалл Ламба, доцент Инженерного колледжа Пиллаи, Нью-Панвел.
Машины опорных векторов (SVM) — Обзор | by Rushikesh Pupale
Классификатор SVM
Машинное обучение включает в себя прогнозирование и классификацию данных, и для этого мы используем различные алгоритмы машинного обучения в соответствии с набором данных.
SVM или машина опорных векторов — это линейная модель для задач классификации и регрессии. Он может решать линейные и нелинейные задачи и хорошо работает для многих практических задач. Идея SVM проста: алгоритм создает линию или гиперплоскость, которая разделяет данные на классы.
В этом сообщении блога я планирую предложить общий обзор SVM. Я расскажу о теории, лежащей в основе SVM, о ее применении для нелинейно разделимых наборов данных, а также о кратком примере реализации SVM на Python. В следующих статьях я рассмотрю математику, стоящую за алгоритмом, и покопаюсь под капотом.
В следующих статьях я рассмотрю математику, стоящую за алгоритмом, и покопаюсь под капотом.
ТЕОРИЯ
В первом приближении SVM находит разделяющую линию (или гиперплоскость) между данными двух классов. SVM — это алгоритм, который принимает данные в качестве входных данных и выводит строку, разделяющую эти классы, если это возможно.
Начнем с проблемы. Предположим, у вас есть набор данных, как показано ниже, и вам нужно классифицировать красные прямоугольники из синих эллипсов (скажем, положительные из отрицательных). Итак, ваша задача — найти идеальную линию, которая разделяет этот набор данных на два класса (скажем, красный и синий).
Найдите идеальную линию/гиперплоскость, которая разделяет этот набор данных на красную и синюю категории.
Несложная задача, верно?
Но, как вы заметили, нет уникальной строки, которая выполняет эту работу. На самом деле у нас есть бесконечные линии, которые могут разделить эти два класса. Так как же SVM находит идеальный???
Так как же SVM находит идеальный???
Возьмем несколько вероятных кандидатов и разберемся сами.
Какая строка, по вашему мнению, лучше всего разделяет данные???
Здесь у нас есть два кандидата, линия зеленого цвета и линия желтого цвета. Какая линия, по вашему мнению, лучше всего разделяет данные?
Если вы выбрали желтую линию, поздравляем, потому что это линия, которую мы ищем. В этом случае визуально довольно интуитивно понятно, что желтая линия классифицирует лучше. Но нам нужно что-то конкретное, чтобы исправить нашу линию.
Зеленая линия на изображении выше очень близка к красной линии. Хотя он классифицирует текущие наборы данных, он не является обобщенной линией, и в машинном обучении наша цель — получить более обобщенный разделитель.
Способ SVM найти лучшую линию
Согласно алгоритму SVM мы находим точки, ближайшие к прямой из обоих классов. Эти точки называются опорными векторами. Теперь мы вычисляем расстояние между линией и опорными векторами. Это расстояние называется запасом. Наша цель – максимизировать маржу. Гиперплоскость, для которой запас максимален, является оптимальной гиперплоскостью.
Теперь мы вычисляем расстояние между линией и опорными векторами. Это расстояние называется запасом. Наша цель – максимизировать маржу. Гиперплоскость, для которой запас максимален, является оптимальной гиперплоскостью.
Оптимальная гиперплоскость с использованием алгоритма SVM
Таким образом, SVM пытается установить границу решения таким образом, чтобы разделение между двумя классами (этой улицей) было как можно шире.
Просто, не правда ли? Давайте рассмотрим немного сложный набор данных, который не является линейно разделимым.
Нелинейно разделимые данные
Эти данные явно не линейно разделимы. Мы не можем провести прямую линию, которая могла бы классифицировать эти данные. Но эти данные могут быть преобразованы в линейно разделимые данные в более высоком измерении. Давайте добавим еще одно измерение и назовем его осью Z. Пусть координаты по оси Z определяются ограничением
z = x²+y²
Таким образом, в основном координата z представляет собой квадрат расстояния точки от начала координат. Давайте нанесем данные на ось Z.
Давайте нанесем данные на ось Z.
Набор данных в более высоком измерении
Теперь данные явно линейно разделимы. Пусть фиолетовая линия, разделяющая данные в более высоком измерении, будет z = k, где k — константа. Поскольку z=x²+y², мы получаем x² + y² = k; что является уравнением окружности. Таким образом, мы можем спроецировать этот линейный разделитель в более высоком измерении обратно в исходные измерения, используя это преобразование.
Граница решения в исходных измерениях
Таким образом, мы можем классифицировать данные, добавляя к ним дополнительное измерение, чтобы они стали линейно разделимыми, а затем проецируя границу решения обратно в исходные измерения, используя математическое преобразование. Но найти правильное преобразование для любого заданного набора данных не так просто. К счастью, мы можем использовать ядра в реализации SVM sklearn для выполнения этой работы.
ГИПЕРПЛОСКОСТЬ
Теперь, когда мы понимаем логику SVM, давайте формально определим гиперплоскость.
Гиперплоскость в n-мерном евклидовом пространстве — это плоское n-1-мерное подмножество этого пространства, которое делит пространство на две несвязанные части.
Например, давайте предположим, что линия является нашим одномерным евклидовым пространством (т. е. допустим, что наши наборы данных лежат на линии). Теперь выберите точку на линии, эта точка делит линию на две части. Линия имеет 1 измерение, а точка имеет 0 измерений. Итак, точка — это гиперплоскость прямой.
Для двух измерений мы видели, что разделительной линией была гиперплоскость. Точно так же для трех измерений плоскость с двумя измерениями делит трехмерное пространство на две части и, таким образом, действует как гиперплоскость. Таким образом, для пространства n измерений у нас есть гиперплоскость n-1 измерений, разделяющая его на две части
CODE
import numpy as np
X = np.
y = np.array([1, 1, 2, 2])
У нас есть точки в X и классы, к которым они принадлежат в Y.
Теперь мы обучаем нашу модель SVM с помощью вышеуказанного набора данных. В этом примере я использовал линейное ядро.
из sklearn.svm import SVC
clf = SVC(kernel='linear')
clf.fit(X, y)
Для прогнозирования класса нового набора данных
Prediction = clf.predict([[0,6 ]])
ПАРАМЕТРЫ НАСТРОЙКИ
Параметры — это аргументы, которые вы передаете при создании классификатора. Ниже приведены важные параметры для SVM-9.0003
1]C:
Он контролирует компромисс между гладкой границей решения и правильной классификацией обучающих точек. Большое значение c означает, что вы правильно получите больше тренировочных очков.
Гладкая граница решения против правильной классификации всех точек
Рассмотрим пример, показанный на рисунке выше. Существует ряд границ решений, которые мы можем провести для этого набора данных. Рассмотрим прямую (зеленого цвета) границу решения, которая довольно проста, но достигается за счет неправильной классификации нескольких точек. Эти ошибочно классифицированные точки называются выбросами. Мы также можем сделать что-то значительно более волнообразное (граница решения небесно-голубого цвета), но при этом мы потенциально получим все правильные точки обучения. Конечно, компромисс с чем-то очень запутанным, очень сложным, как это, заключается в том, что, скорее всего, он не будет так хорошо обобщаться на наш тестовый набор. Так что что-то простое, более прямое может быть лучшим выбором, если вы посмотрите на точность. Большое значение c означает, что вы получите более сложные кривые решений, пытающиеся уместиться во всех точках. Выяснение того, насколько вы хотите иметь гладкую границу решения по сравнению с той, которая делает все правильно, является частью искусства машинного обучения. Поэтому попробуйте разные значения c для вашего набора данных, чтобы получить идеально сбалансированную кривую и избежать чрезмерной подгонки.
Существует ряд границ решений, которые мы можем провести для этого набора данных. Рассмотрим прямую (зеленого цвета) границу решения, которая довольно проста, но достигается за счет неправильной классификации нескольких точек. Эти ошибочно классифицированные точки называются выбросами. Мы также можем сделать что-то значительно более волнообразное (граница решения небесно-голубого цвета), но при этом мы потенциально получим все правильные точки обучения. Конечно, компромисс с чем-то очень запутанным, очень сложным, как это, заключается в том, что, скорее всего, он не будет так хорошо обобщаться на наш тестовый набор. Так что что-то простое, более прямое может быть лучшим выбором, если вы посмотрите на точность. Большое значение c означает, что вы получите более сложные кривые решений, пытающиеся уместиться во всех точках. Выяснение того, насколько вы хотите иметь гладкую границу решения по сравнению с той, которая делает все правильно, является частью искусства машинного обучения. Поэтому попробуйте разные значения c для вашего набора данных, чтобы получить идеально сбалансированную кривую и избежать чрезмерной подгонки.