Содержание
С 30 мая действует новая форма отчета СЗВ-М для ПФР
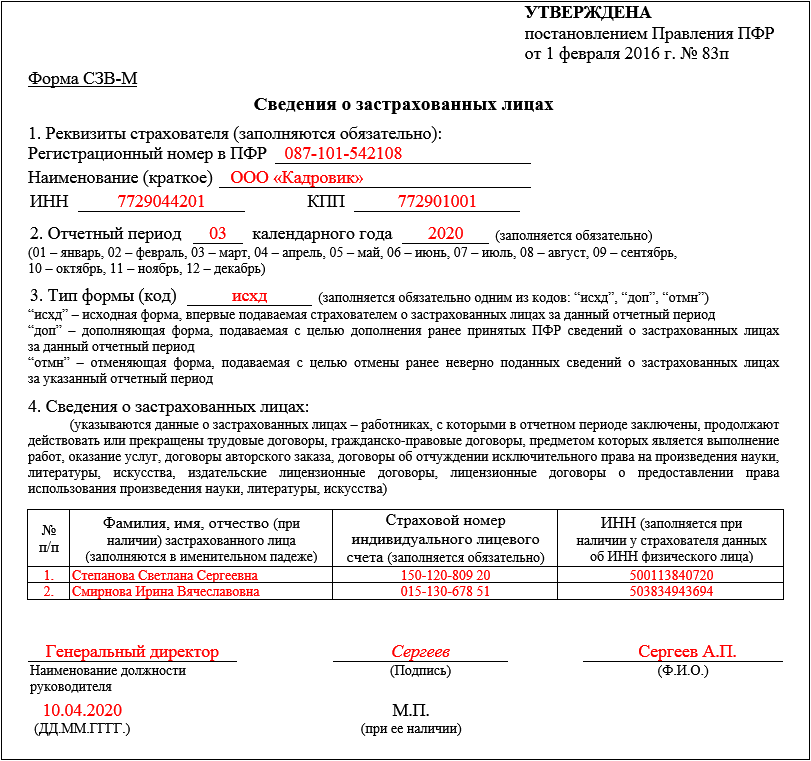
Правление ПФР постановлением от 15 апреля 2021 года № 103п обновило форму отчета СЗВ-М («Сведения о застрахованных лицах»). Вступила в силу новая форма 30 мая 2021 года. Поэтому использовать ее работодатели должны уже при отправке отчетности за май.
Напомним, что СЗВ-М – это форма ежемесячной отчетности в ПФР, которую сдают все организации и ИП, имеющие наемных работников по трудовым договорам или договорам ГПХ, включая сотрудников, находящихся в декрете или отпуске, а также тех, с кем в отчетном месяце был расторгнут рабочий договор.
Сроки сдачи СЗВ-М – до 15-го числа месяца, следующего за отчетным. Так, отчет по новой форме СЗВ-М за май нужно сдать до 15 июня 2021 года.
Что изменилось в бумажной форме СЗВ-М
Существенно – ничего. Основных изменений три:
— Правила заполнения формы вынесены в отдельный порядок, что абсолютно ничего не меняет в вашей работе при заполнении формы.
— Тип формы теперь нужно прописывать полностью, вместо используемых ранее сокращений. Например: «исходящая» вместо «исхд».
Например: «исходящая» вместо «исхд».
— Последнее скорее уточнение, а не изменение. СЗВ-М теперь нужно сдавать на директоров, являющихся единственными учредителями компании.
Что изменилось в электронной форме СЗВ-М
Ничего. Электронная форма СЗВ-М осталась неизменной. С порядком ее сдачи вы можете ознакомиться в постановлении Правления ПФР от 7 декабря 2016 года № 1077п.
Дело в том, что при отправке электронной формы часть изменений, внесенных в бумажный вариант, не будут иметь значения. Например, изменение об отмене сокращений не играет никакой роли для электронной СЗВ-М, так как в электронном варианте тип формы указывается с помощью кода, то есть его не нужно прописывать словами.
Отчетность в ПФР – без проблем с сервисами Такском
Форма отчета СЗВ-М максимально простая и не громоздкая, однако многие бухгалтеры и кадровики совершают ошибки при ее заполнении. А еще это одна из форм, по которой ежедневно выписывается наибольшее число штрафов.
Максимально минимизировать вероятность ошибки можно, используя сервисы для электронной отчетности. Тем более, что в электронной СЗВ-М, как мы уже сообщили, ничего не поменялось.
Во-первых, вам не придется следить за новостями об обновлениях – все формы отчетности, представленные в программных продуктах Такском, актуальны на сегодняшний день и отвечают последним изменениям законодательства.
Во-вторых, при заполнении форм отчетности вы видите текстовые подсказки по их заполнении – очень удобно, чтобы не обращаться за помощью к дополнительным интернет ресурсам.
В-третьих, во всех сервисах Такском для отчетности через интернет встроена автоматическая система проверки на ошибки, которая не даст вам отправить некорректно заполненный отчет или отчет с пропущенными полями.
Узнать подробнее о преимуществах электронной отчетности и подобрать тарифный план вы можете здесь.
ПФР СЗВ-М
Отправить
Запинить
Твитнуть
Поделиться
Свои замечания и предложения отправляйте на brand@taxcom.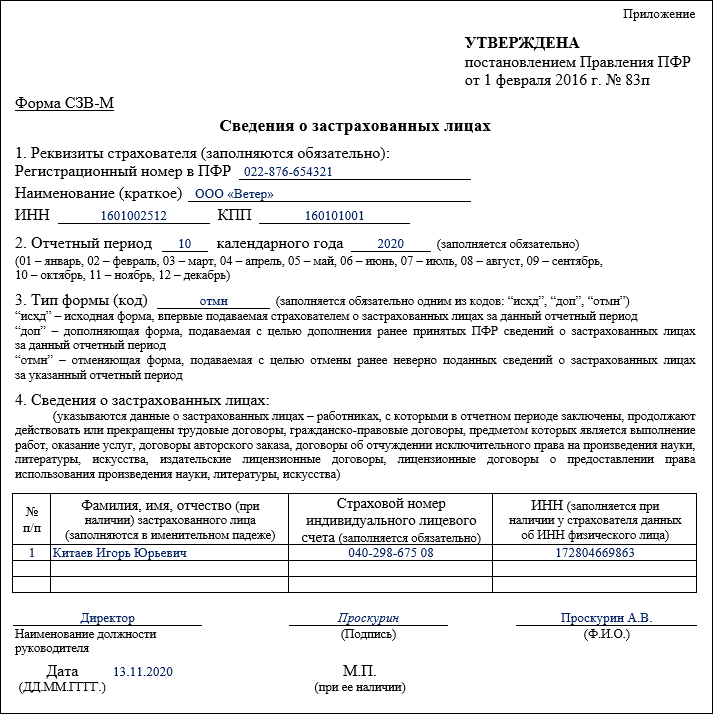 ru
ru
Нужно ли сдавать нулевой отчет СЗВ-М в 2022 году – сроки подачи отчета и образец заполнения
Оглавление
Скрыть
Отчётность по форме СЗВ-М
В каких случаях оформляется нулевой СЗВ-М
Как заполнять нулевой СЗВ-М
Сроки подачи нулевого отчёта СЗВ-М
Нулевой отчёт СЗВ-М при отсутствии штатных сотрудников
Отчётность по форме СЗВ-М
Все работодатели считаются страхователями по ОПС и обязаны предоставлять в территориальные органы документы, необходимые для ведения персонифицированного учёта согласно статье 14 ФЗ № 167. Одним из таких документов является форма СЗВ-М.
Она включает в себя сведения о застрахованных лицах, с которыми в отчётном месяце заключён, действует или расторгнут любой из следующих договоров:
- Трудовой
- Гражданско-правовой договор, предметом которого является выполнение работ или оказание услуг
- Об отчуждении исключительного права на произведения науки, литературы или искусства
Упростите себе жизнь — сформируйте отчётность в 2 клика с помощью сервиса «Моё дело».
Система все рассчитывает автоматически, а также заполняет документы для подачи в налоговую службу и пенсионный фонд.
Попробовать бесплатно
В форме СЗВ-М должны указываться данные о всех работниках, которые трудились в компании в отчётном месяце, в том числе уволенных, взявших больничный за свой счёт и тех, кто не получил никаких выплат.
Работники, заключившие договоры ГПХ, авторские или об отчуждении прав, отражаются на общих основаниях — так же как и по трудовым договорам.
Следует помнить, что предприятия со штатом 11 сотрудников и более могут отправлять отчёты только в электронном виде. Если же трудоустроено 10 человек и менее, то принимаются и документы на бумажном носителе.
В каких случаях оформляется нулевой СЗВ-М
Нулевой формы СЗВ-М по определению быть не может: заполненный бланк отчётности подлежит обязательной сдаче.
Однако в юридической и налоговой практике уже закрепилось понятие «нулевой отчётности», например, нулевые декларации всё же подаются. Под условно нулевой формой СЗВ-М обычно понимают отчёт, в котором указан только директор компании, в которой нет других сотрудников. Это правило касается исключительно организаций.
Под условно нулевой формой СЗВ-М обычно понимают отчёт, в котором указан только директор компании, в которой нет других сотрудников. Это правило касается исключительно организаций.
То есть, если в компании числится хотя бы один сотрудник, обычно это генеральный директор и учредитель в одном лице, то отчётность необходимо подавать, хотя это бывает не совсем очевидно. Даже если в штате вообще нет рядовых сотрудников, учредитель считается руководителем фирмы, то есть за ним закреплена должность генерального директора.
Подобные ситуации возникают, например, если зарегистрировать фирму под конец календарного месяца, при финансовых трудностях или приостановке деятельности, когда от услуг наёмных работников приходится отказываться.
Предоставлять сведения об единственном учредителе, ставшем генеральным директором, организация должна независимо от того, выплачивается ему заработная плата или нет. На это не влияет даже отсутствие деятельности – всё равно придётся отчитаться. ПФР подтверждает это в письме от 20.03.2018 № ЛЧ-08-24/5721.
ПФР подтверждает это в письме от 20.03.2018 № ЛЧ-08-24/5721.
Кроме того, если сотрудники организации за отчётный период не получили выплат, они не перестают быть застрахованными лицами и должны быть внесены в бланк СЗВ-М.
Отправка данных о застрахованных лицах является обязательной, однако у этого правила есть исключения. Так, от подачи отчёта СЗВ-М освобождены:
- Крестьянские и фермерские хозяйства без наёмных работников
- ИП, арбитражные управляющие, адвокаты с частной практикой и нотариусы, которые платят фиксированные страховые взносы только за себя
- Работодатели за иностранных граждан и лиц без гражданства, временно находящихся на территории РФ или работающих удалённо в соответствии со статьёй 7 ФЗ № 167
- Работодатели за военнослужащих, сотрудников внутренних органов и ФСБ за исключением вольнонаёмных согласно тому же закону
Важно понимать, что эти категории граждан освобождены от сдачи СЗВ-М не из-за отсутствия работников или заработной платы, а согласно законодательству.
То есть, индивидуальные предприниматели без сотрудников вообще не обязаны сдавать форму СЗВ-М. Если же они привлекает наёмную силу, то заполняют отчёты по общим правилам. В этом случае необходимо указать только нанятый персонал, сам ИП данные о себе вносить не должен. Это следует из пояснений ПФР.
Как заполнять нулевой СЗВ-М
Так как нулевого СЗВ-М не бывает, бухгалтеры используют условно нулевой. В таком бланке могут быть отражены только данные директора компании. В остальном же он заполняется как обычный отчёт по общим правилам.
Необходимо заполнить поле с регистрационным номером компании в ПФР и внести значения в графы ИНН и КПП. Ниже проставить отчётный период в цифровой форме и год, за которые сдаётся отчёт.
Далее отметить тип формы в виде буквенного кода. В случае нормативной подачи в обычном графике это будет «исхд». После обязательно следует внести в бланк следующие данные:
- ФИО руководителя
- Страховой номер индивидуального лицевого счёта (СНИЛС) – он должен быть в обязательном порядке
- ИНН
Однако, важно отметить, что позиция ПФР и Минтруда по поводу нулевой формы неоднократно менялась.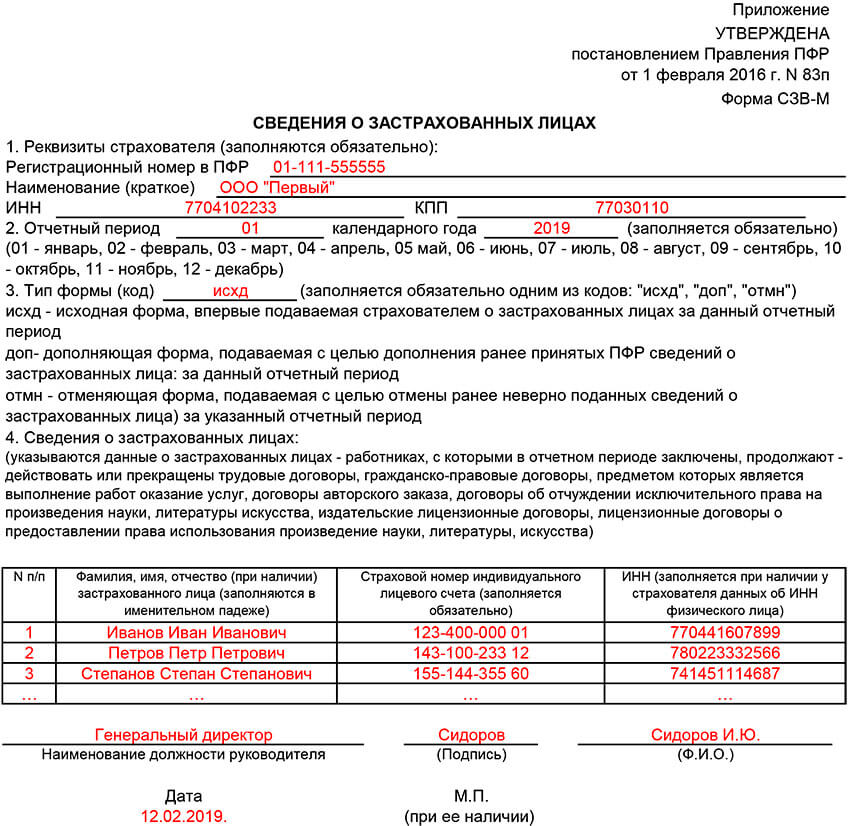 В 2016 году было заявлено, что если фирма не ведёт никакой деятельности, а с директором не заключён трудовой договор, то СЗВ-М можно не подавать. А в письме ПФР от 20.03.2018 утверждается уже обратное. Также здесь следует учитывать и судебную практику, так как в случае признания поданных сведений неправильными или неполными, предусмотрены штрафные санкции.
В 2016 году было заявлено, что если фирма не ведёт никакой деятельности, а с директором не заключён трудовой договор, то СЗВ-М можно не подавать. А в письме ПФР от 20.03.2018 утверждается уже обратное. Также здесь следует учитывать и судебную практику, так как в случае признания поданных сведений неправильными или неполными, предусмотрены штрафные санкции.
Боитесь допустить ошибку в отчёте СЗВ-М?
Создайте бланк с помощью сервиса «Моё дело». У нас исключены ошибки.
Создать бесплатно отчёт
В 2022 году лучшим решением будет перестраховаться и указать данные директора, даже если с ним нет оформленных трудовых отношений, поскольку письменные разъяснения официальных инстанций не всегда принимаются в качестве доказательств. Кроме того, можно обратиться к экспертам компании «Моё дело» и получить комментарии по поводу того, как следует поступить.
На единственного сотрудника – директора фирмы бланк СЗВ-М будет выглядеть так. Все поля заполняются как обычно, единственное отличие – в 4 разделе должны быть записи только с данными руководителя компании.
Все поля заполняются как обычно, единственное отличие – в 4 разделе должны быть записи только с данными руководителя компании.
Пример заполнения «нулевого» СЗВ-М
Сроки подачи нулевого отчёта СЗВ-М
Так как не существует нулевой формы СЗВ-М (она лишь включает в себя минимум информации), то и отчитываться следует на общих основаниях.
Согласно статье 11 ФЗ №27 01.04.1996, отчётность нужно предоставлять ежемесячно не позднее 15 числа месяца, следующего за отчётным. Если крайний срок сдачи формы выпадает на праздничный или выходной день, то сдавать её следует в ближайший рабочий день.
Можно сдать и раньше при необходимости, однако следует удостовериться, что до конца месяца штат не пополнится новыми сотрудниками. В противном случае последует штраф от ПФР за предоставление неполных сведений о застрахованных лицах.
Форма СЗВ-М сдаётся в территориальный орган ПФР по месту регистрации страхователя согласно п.1 статьи 11 закона № 27-ФЗ. Филиалы, имеющие собственный действующий счёт в банке, обязаны подавать форму отдельно. В этом случае в отчёте в графе ИНН указывается значение основного подразделения, а в КПП – обособленного.
В этом случае в отчёте в графе ИНН указывается значение основного подразделения, а в КПП – обособленного.
Даты подачи формы СЗВ-М в 2022 году
Нулевой отчёт СЗВ-М при отсутствии штатных сотрудников
Поскольку указывать в форме СЗВ-М необходимо всех застрахованных лиц, у работодателей часто возникает вопрос: чьи данные вносить при отсутствии штатных сотрудников?
Кроме того, в штате любого юридического лица в обязательном порядке должен числиться хотя бы один сотрудник, даже если деятельность не ведётся в силу каких-либо причин. Обычно этим работником и выступает генеральный директор организации, притом не важно оформлено это официально или нет, то есть вне зависимости от наличия трудового договора.
А так как заявления уполномоченных органов разнятся, чтобы избежать неприятностей или даже судебных разбирательств, рекомендуется подавать форму СЗВ-М с данными руководителя компании, если нет других официально оформленных сотрудников.
Также следует регулярно просматривать новости судебной практики и мониторить ситуацию в информационном поле на предмет новых распоряжений со стороны официальных ведомств в 2022 году.![]()
Зарегистрируйтесь в интернет-бухгалтерии «Моё дело»
И получите бесплатную круглосуточную экспертную поддержку по всем вопросам бухгалтерского учёта и налогообложения.
Получить доступ
Машинное обучение
— Как сообщить о модели SVM третьей стороне после перекрестной проверки?
спросил
Изменено
8 лет, 8 месяцев назад
Просмотрено
528 раз
$\begingroup$
У меня проблема с бинарной классификацией. Я обучил свой набор данных с помощью машины опорных векторов (SVM). Теперь я хочу сообщить о модели, которую я обучил, третьей стороне, чтобы они могли ее использовать.
Для основной задачи SVM уравнение классификатора имеет вид
y = w.x + b
 x + b
x + b
, где w — вектор весов, b — константа, а x — новый экземпляр. В зависимости от значения y мы можем предсказать класс.
Я мог сообщить весовой вектор w и константу b, которые были получены моей моделью.
Но если я хочу протестировать свою модель с помощью перекрестной проверки, как мне сообщить о своей модели? Каждый раз, когда я выполняю перекрестную проверку, уравнение построенного классификатора будет меняться.
- машинное обучение
- SVM
- перекрестная проверка
- оценка модели
$\endgroup$
$\begingroup$
Вы выполняете перекрестную проверку, чтобы оценить производительность обобщения для данного кортежа параметров. Получив оценку, вы обучаете другую модель на полном обучающем наборе , используя те же параметры, и передаете эту модель третьей стороне.
$\endgroup$
3
$\begingroup$
Каждый раз, когда я выполняю перекрестную проверку, уравнение построенного классификатора будет меняться.
Обычно существует ряд предположений, связанных с перекрестной проверкой:
Прежде всего, вы предполагаете, что каждая из многих суррогатных моделей эквивалентна (по крайней мере, по своей предсказательной способности) модели, обученной в целом. набор данных.
Заметив, что это предположение нарушается (симптомом этого нарушения является пессимистический уклон перекрестной проверки), вы можете сделать более слабое предположение, что, по крайней мере, суррогатные модели эквивалентны друг другу. Это позволяет объединить результаты их тестирования.
Если даже это предположение не сработает, вам придется признать тот факт, что ваши модели (или их прогнозы) нестабильны .

Итак, во-первых, пока 1. или хотя бы 2. выполняется на уровне стабильных векторов поддержки, с вашей отчетностью не возникает практических проблем. Различные наборы опорных векторов могут привести к моделям, которые в основном дают одинаковые прогнозы. Пока это так, проблем по-прежнему нет: у вас есть разные векторы поддержки, которые, по сути, описывают одну и ту же границу решения.
Единственная ситуация, когда эти изменения становятся проблематичными, — это когда прогнозы становятся нестабильными. Но напр. с повторной $k$-кратной перекрестной проверкой вы можете измерить, есть ли проблема нестабильных прогнозов. (См., например, Доверительный интервал для перекрестной проверки точности классификации)
Если прогнозы стабильны, вы можете сообщить о модели, обученной на всем наборе данных.
Если есть, то есть 3 возможности.
- Вы можете сообщить о результатах проверки, включая наблюдаемую нестабильность (проверка означает демонстрацию того, что ваша модель выполняет свою работу, и стабильные прогнозы, вероятно, являются частью этого).
- И вы можете добавить к своему профессиональному опыту, что вы переоснастили модель, и перейти на более ограниченную.
(Строго говоря, для этого потребуется собственный независимый тестовый набор. Но вы можете избежать этого по практическим причинам с повторной перекрестной проверкой, если вы просто сделаете шаг один раз в сторону менее сложной модели . Если вы сделаете это, я бы рекомендуем сообщить читателю, что должна была быть проведена еще одна проверка, но это было невозможно по практическим соображениям, и сообщить полную «историю» разработки модели.) - Немного загадочно для SVM, но вы можете объединить суррогатные модели в ансамблевый классификатор.

$\endgroup$
5
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
Метод опорных векторов
с практической реализацией | Амир Али | Wavy AI Research Foundation
В этой главе мы обсудим алгоритм машины опорных векторов, который также используется как для классификации, так и для задачи регрессии, а также его алгоритм машинного обучения с учителем.
Эта статья состоит из трех частей:
- Что такое метод опорных векторов?
- Как работает машина опорных векторов?
- Практическая реализация SVM в Scikit Learn.
Метод опорных векторов — это мощный алгоритм в алгоритме машинного обучения с учителем.
Используется как для задач классификации, так и для задач регрессии. Однако в основном он используется в задачах классификации.
В SVM мы разделяем точку данных на атрибут класса, используя гиперплоскость для разделения наших данных.
В этом алгоритме мы размещаем каждый элемент данных в виде точки в n-мерном пространстве (где n — количество имеющихся у вас объектов) со значением определенной координаты. Затем мы выполняем классификацию, находя гиперплоскость, которая очень хорошо различает два класса
Короче говоря, Поддержка, Вектор — это просто координата индивидуального наблюдения. SVM — это граница, которая лучше всего разделяет два класса по линии гиперплоскости, как показано на рисунке выше.
Ванильный SVM представляет собой тип линейного сепаратора. Предположим, мы хотим отделить черные круги от белых выше, нарисовав линию. Обратите внимание, что существует бесконечное количество строк, которые выполнят эту задачу. SVM, в частности, находят линию «максимальной маржи» — это линия «посередине». Интуитивно это работает хорошо, потому что допускает шум и наиболее терпимо к ошибкам с обеих сторон.
Это все (бинарная) SVM rea. Мы проводим прямую линию через наши данные посередине, чтобы разделить их на два класса. Но что, если нам нужна не прямая линия, а изогнутая? Мы достигаем этого не рисуя кривые, а «поднимая» наблюдаемые особенности в более высокие измерения. Например, если мы не можем провести линию в пространстве (x1, x2), мы можем попробовать добавить третье измерение (x1, x2, x1 * x2). Если мы спроецируем «линию» (фактически называемую «гиперплоскостью») в этом более высоком измерении вниз на наше исходное измерение, она будет выглядеть как кривая.
2.
 1: Как SVM работает в линейных задачах?
1: Как SVM работает в линейных задачах?
Классификацию можно рассматривать как задачу разделения классов в пространстве признаков.
Вот два класса красный класс и синий класс и задача состоит в том, чтобы найти границу между этими двумя классами и провести отдельную гиперплоскостную линию.
В методе опорных векторов мы проводим оптимальную линию, чтобы разделить эти два класса.
Здесь мы выбираем три опорных вектора для начала.
Это S1, S2 и S3.
Здесь мы будем использовать векторы, дополненные 1, в качестве ввода смещения и для ясности мы будем различать их с помощью тильды.
Это
Теперь нам нужно найти 3 параметра α1, α2 и α3 на основе следующих 3 линейных уравнений:
После упрощения получаем
-3,25 α2= -3,25 и α3=3,5
Гиперплоскость, которая отличает положительный класс от отрицательного класса, определяется как:
Это ожидаемая поверхность принятия решений LSVM.
2.2: Как SVM работает в нелинейной задаче?
Мы смотрим на линейный тип в части 1 нашего алгоритма SVM. Здесь мы рассмотрим пример, подобный приведенному ниже, и выясним, как проводить классификацию.
Очевидно, что между красным классом и синим классом нет четкой разделяющей гиперплоскости.
Здесь нам нужно найти нелинейную функцию отображения fi, которая может преобразовать эти данные в новое пространство признаков, где можно найти разделяющую гиперплоскость.
Рассмотрим следующую функцию отображения.
Теперь давайте преобразуем векторы синего и красного классов, используя функцию нелинейного отображения fi
После применения функции отображения мы преобразуем все точки, как показано на рис.
Теперь наша задача состоит в том, чтобы найти подходящие опорные векторы для классификации этих двух классов
Здесь мы выбираем следующие 3 опорных вектора:
Здесь мы будем использовать векторы, дополненные 1, в качестве входных данных смещения, и для ясности мы будем различать их с овер-тильдой.
То есть
Теперь нам нужно найти 3 параметра α1, α2 и α3 на основе следующих 3 линейных уравнений:
После упрощения получаем
0,859 α2= 0,859 и α3=-1,4219
Гиперплоскость, которая отличает положительный класс от отрицательного, определяется как:
Подставляя значения, которые мы получаем:
Наши векторы увеличены с уклоном.
Следовательно, мы можем приравнять вход в качестве гиперплоскости со смещением b.
Следовательно, уравнение разделяющей гиперплоскости
Это ожидаемая поверхность решения не LSVM.
Примечание: Если вам нужна эта статья, загляните в мой профиль academia.edu .
3.1: SVM для подхода к классификации
Описание данных:
Для демонстрации маркетинговой модели RFMTC (модифицированная версия RFM) в этом исследовании использовалась база данных доноров Центра переливания крови в городе Синь-Чу на Тайване. Центр передает свой автобус службы переливания крови в один из университетов в городе Синь-Чу для сбора донорской крови примерно каждые три месяца. Для построения модели FRMTC мы случайным образом выбрали 748 доноров из базы данных доноров. Эти 748 данных о донорах, каждая из которых включала R (давность — месяцы с момента последней сдачи крови), F (частота — общее количество донаций), M (денежный показатель — общее количество донорской крови в куб. м), T (время — месяцы с момента первой сдачи) и бинарная переменная, показывающая, сдавал ли он/она кровь в марте 2007 г. (1 означает сдачу крови; 0 означает отсутствие сдачи крови).
Центр передает свой автобус службы переливания крови в один из университетов в городе Синь-Чу для сбора донорской крови примерно каждые три месяца. Для построения модели FRMTC мы случайным образом выбрали 748 доноров из базы данных доноров. Эти 748 данных о донорах, каждая из которых включала R (давность — месяцы с момента последней сдачи крови), F (частота — общее количество донаций), M (денежный показатель — общее количество донорской крови в куб. м), T (время — месяцы с момента первой сдачи) и бинарная переменная, показывающая, сдавал ли он/она кровь в марте 2007 г. (1 означает сдачу крови; 0 означает отсутствие сдачи крови).
Часть 1: Предварительная обработка данных:
1.1 Импорт библиотек
На этом этапе мы импортируем три библиотеки в части предварительной обработки данных. Библиотека — это инструмент, который можно использовать для выполнения определенной работы. Прежде всего, мы импортируем библиотеку numpy , используемую для многомерного массива, затем импортируем библиотеку pandas , используемую для импорта набора данных, и, наконец, мы импортируем библиотеку matplotlib , используемую для построения графика.
1.2 Импорт набора данных
На этом этапе мы импортируем набор данных, чтобы использовать библиотеку pandas . После импорта нашего набора данных мы определяем наш Predictor и целевой атрибут. здесь мы называем « X » предсказателем и целевым атрибутом, который мы называем здесь « y ».
1.3 Разделение набора данных для тестирования и обучения
На этом этапе мы разделяем наш набор данных на тестовый набор и набор для обучения, 80% набора данных для обучения и оставшиеся 20% для тестов.
1.4 Масштабирование признаков
Масштабирование признаков является наиболее важной частью предварительной обработки данных. Если мы видим наш набор данных, то какой-то атрибут содержит информацию в числовом значении, какое-то значение очень высокое, а какое-то очень низкое, если мы видим возраст и предполагаемую зарплату. Это вызовет некоторые проблемы в нашей модели оборудования, чтобы решить эту проблему, мы устанавливаем все значения в одной шкале. Есть два метода решения этой проблемы: первый — нормализовать, а второй — стандартное масштабирование.
Это вызовет некоторые проблемы в нашей модели оборудования, чтобы решить эту проблему, мы устанавливаем все значения в одной шкале. Есть два метода решения этой проблемы: первый — нормализовать, а второй — стандартное масштабирование.
Здесь мы используем стандартный импорт Scaler из библиотеки Sklearn.
Часть 2. Создание модели SVM:
В этой части мы моделируем нашу модель с помощью библиотеки Scikit Learn.
2.1 Импорт библиотек
На этом этапе мы создаем нашу модель, для этого сначала мы импортируем модель из библиотеки Scikit Learn.
2.2 Инициализация нашей модели SVM
На этом этапе мы инициализируем нашу модель, а в модели классификатора SVM берем линейное ядро.
2.3 Подгонка модели
На этом этапе мы подгоняем данные обучения к нашей модели X_train, y_train — это наши данные обучения.
Часть 3. Получение результатов прогнозирования и точности:
Получение результатов прогнозирования и точности:
В этой части мы делаем прогноз для набора данных нашего тестового набора и визуализируем результат с помощью библиотеки matplotlib .
3.1 Прогнозирование набора тестов Результат
На этом этапе мы прогнозируем результат набора тестов.
3.2 Метрика путаницы
На этом этапе мы создаем метрику путаницы для результата нашего тестового набора, чтобы сделать это, мы импортируем матрицу путаницы из sklearn.metrics, затем в матрице путаницы мы передаем два параметра: сначала y_test, который является фактический результат набора тестов, а второй — y_pred, который предсказал результат.
3.3 Оценка точности
На этом этапе мы вычисляем оценку точности на основе фактического результата теста и прогнозируем результаты теста.
Если вам нужен набор данных и код, вы также можете проверить мой профиль Github .
3.2: SVM для регрессионного подхода
Набор данных Описание:
Фрейм данных СПИДа имеет 570 строк и 6 столбцов. Хотя обо всех случаях СПИДа в Англии и Уэльсе необходимо сообщать в Центр эпиднадзора за инфекционными заболеваниями, часто между моментом постановки диагноза и моментом сообщения о нем проходит значительная задержка. При оценке распространенности СПИДа необходимо учитывать неизвестное число случаев, которые были диагностированы, но не зарегистрированы. Набор данных здесь отражает зарегистрированные случаи СПИДа, диагностированные с 19 июля.83 и до конца 1992 года. Данные перекрестно классифицированы по дате постановки диагноза и времени задержки в сообщении о случаях.
Часть 1: Предварительная обработка данных:
1.1 Импорт библиотек
На этом этапе мы импортируем три библиотеки в части предварительной обработки данных. Библиотека — это инструмент, который можно использовать для выполнения определенной работы. Прежде всего, мы импортируем библиотеку numpy , используемую для многомерного массива, затем импортируем библиотека pandas , используемая для импорта набора данных, и, наконец, мы импортируем библиотеку matplotlib , используемую для построения графика.
Прежде всего, мы импортируем библиотеку numpy , используемую для многомерного массива, затем импортируем библиотека pandas , используемая для импорта набора данных, и, наконец, мы импортируем библиотеку matplotlib , используемую для построения графика.
1.2 Импорт набора данных
На этом этапе мы импортируем набор данных, чтобы использовать библиотеку pandas . После импорта нашего набора данных мы определяем наш Predictor и целевой атрибут. здесь мы называем « X » предсказателем и целевым атрибутом, который мы называем здесь « y ».
1.3 Разделить набор данных для тестирования и обучения
На этом этапе мы разделяем наш набор данных на тестовый набор и набор для обучения, а также 80% набора данных для обучения и оставшиеся 20% для тестов.
1.4 Масштабирование признаков
Масштабирование признаков является наиболее важной частью предварительной обработки данных. Если мы видим наш набор данных, то какой-то атрибут содержит информацию в числовом значении, какое-то значение очень высокое, а какое-то очень низкое, если мы видим возраст и предполагаемую зарплату. Это вызовет некоторые проблемы в нашей модели оборудования, чтобы решить эту проблему, мы устанавливаем все значения в одной шкале. Есть два метода решения этой проблемы: первый — нормализовать, а второй — стандартное масштабирование.
Если мы видим наш набор данных, то какой-то атрибут содержит информацию в числовом значении, какое-то значение очень высокое, а какое-то очень низкое, если мы видим возраст и предполагаемую зарплату. Это вызовет некоторые проблемы в нашей модели оборудования, чтобы решить эту проблему, мы устанавливаем все значения в одной шкале. Есть два метода решения этой проблемы: первый — нормализовать, а второй — стандартное масштабирование.
Здесь мы используем стандартный импорт Scaler из библиотеки Sklearn.
Часть 2. Построение регрессионной модели SVM:
В этой части мы моделируем нашу модель с помощью библиотеки Scikit Learn.
2.1 Импорт библиотек
На этом этапе мы создаем нашу модель, для этого сначала мы импортируем модель из библиотеки Scikit Learn.
2.2 Инициализация нашей модели
На этом шаге мы инициализируем нашу модель нашей модели регрессора дерева решений. Итак, здесь RBF — это ядро Гаусса.
Итак, здесь RBF — это ядро Гаусса.
2.3 Подгонка модели
На этом этапе мы подгоняем данные обучения к нашей модели X_train, y_train — это наши данные обучения.
Часть 3: Создание прогноза и визуализация результата:
В этой части мы делаем прогноз для нашего набора данных тестового набора и визуализируем результат с помощью библиотеки matplotlib .
3.1 Прогнозирование набора тестов Результат
На этом этапе мы прогнозируем результат набора тестов.
3.2 Визуализация нашего результата
На этом этапе мы визуализируем наш тестовый набор данных.
Если вам нужен набор данных и код, вы также можете проверить мой профиль Github .
Если вам понравилась эта статья, обязательно нажмите ❤ ниже, чтобы порекомендовать ее, а если у вас есть какие-либо вопросы, оставьте комментарий , и я сделаю все возможное, чтобы ответить.